
前提
很多时候我们可以会有这样子的感受,自己代码的接口设计混乱、代码耦合比较严重、一个类处理的事情太多、代码扩展性差、代码的维护工作量大、代码维护容易引发新的问题等等。其实出现这样子的问题主要是缺乏一些指导性的原则,或者是知道这些指导原则却没有实战项目中体会到这种原则带来的优势,以致于在项目开发中没有得到足够的重视。
今天我们就来讨论一下面向对象六大原则,以及其优点,希望能让大家有个清晰的认识,以便日后能写出优秀的代码。
1.单一职责原则
单一职责原则英文名称为Single Responsibility Principle,简称SRP.简单的说就是一个接口,一个类或者一个方法只做一件事情。但这里有个问题就是单一职责的定义并没有一个清晰的界定,也取决于开发者的看待问题的角度、开发者的经验等等。试想一下如果你遵守了此原则,那么你的接口、类或者方法就划分得很细,每个接口、类或者方法只有比较单一的职责,这不就是高内聚、低耦合么!此乃软件工程开发的高境界。
SRP单一职责原则的定义是:应该有且仅有一个原因引起类的变更。
我们使用一个打电话的例子来说明一下。我们打电话一般会有4个过程发生:拨号、通话、回应、挂机。那我们写一个接口,其类图如图: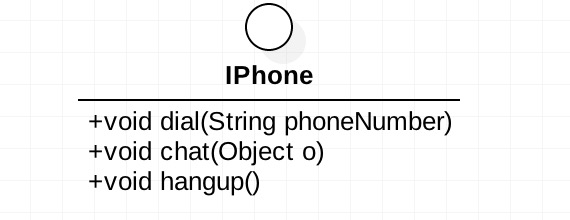 我们再来看看其接口的代码定义:
我们再来看看其接口的代码定义:
public interface Iphone {
//拨通电话
public void dial(String phoneNumber);
//通话
public void chat(Object o);
//挂断电话
public void hangup();
}
大家觉得这样子的接口定义有问题吗?是否觉得自己平时也是这么做的呢?是的,这个接口接近于完美,但只是接近完美。单一职责原则要求一个接口或者类只有一个原因引起变化,也就是一个接口或类只有一个职责。它就负责一件事情,看看上面的接口只负责一件事情吗?是只有一个原因引起变化吗?好像不是。。
IPhone这个接口可不是只有一个职责,它包含两个职责:一个是协议管理,另一个是数据传送。拨通电话和挂断电话属于协议管理,而通话属于数据传送。这样我们就发现IPhone接口包含两个职责,而且这两个职责不相互影响。那就考虑将其拆分成两个接口,其类图如下所示: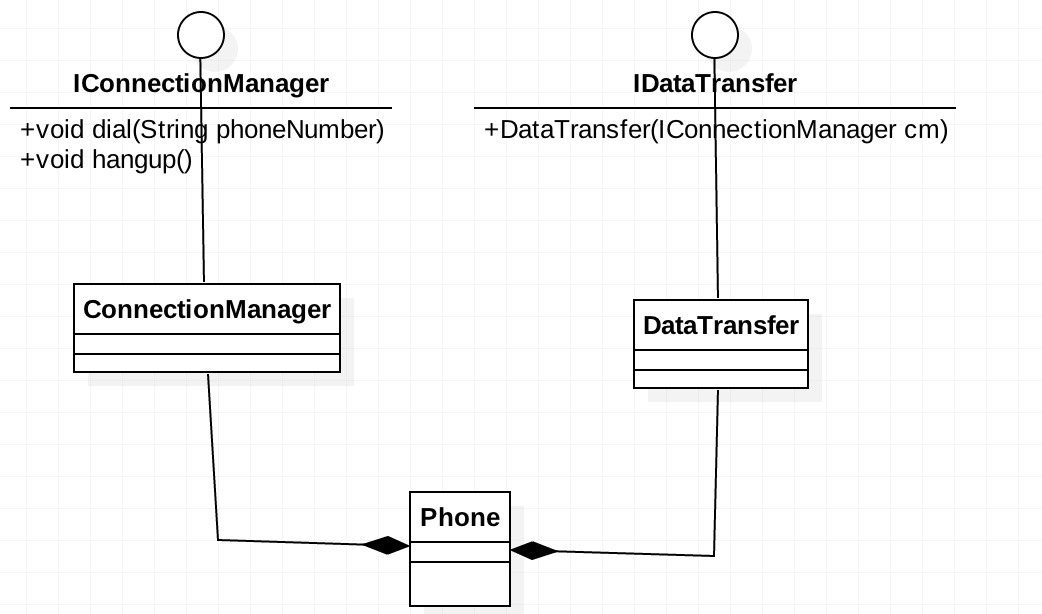 上面这个类图看起来有些复杂,它完全满足单一职责原则,每一接口的职责分明,但这里有一个问题,就是一个
上面这个类图看起来有些复杂,它完全满足单一职责原则,每一接口的职责分明,但这里有一个问题,就是一个phone类要将两个接口的实现类组合,而组合是强耦合关系,两个类都有共同的生命周期,这样的强耦合关系还不如直接实现一个接口来得好,而且还增加了类的复杂性,多增加了两个类。经过这样的思考后,我们把类图更改一下: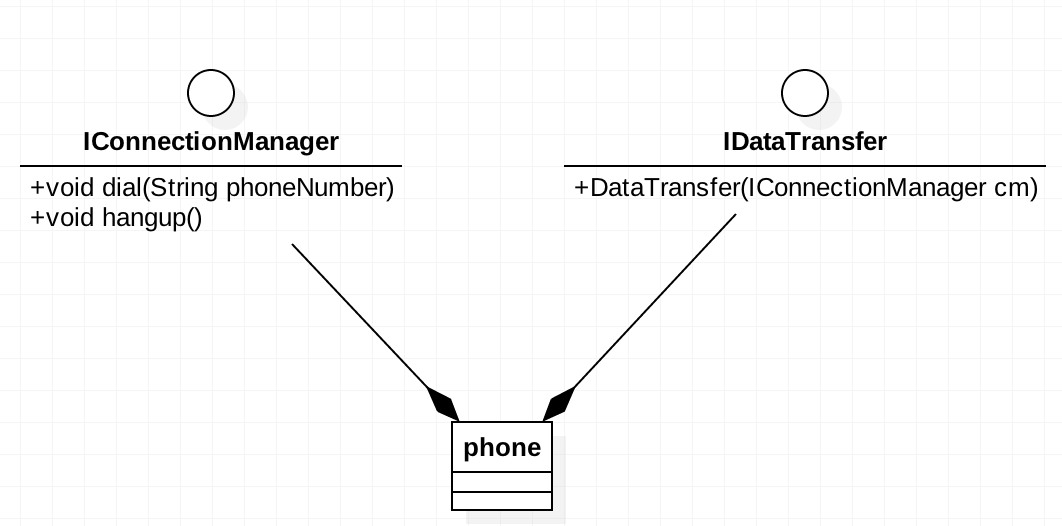 这样的实现是完美的,一个类实现两个接口。但有人会问这一个类不是完成了两个职责?大家不要忘了我们是面向接口编程,我们对外暴露的接口,而从接口上来看我们是满足单一职责的。而且要真正实现类的单一职责,那样子就需要使用组合模式了,这会引起类间耦合过重、类的数量增加等问题,额外的增加程序的复杂度。
这样的实现是完美的,一个类实现两个接口。但有人会问这一个类不是完成了两个职责?大家不要忘了我们是面向接口编程,我们对外暴露的接口,而从接口上来看我们是满足单一职责的。而且要真正实现类的单一职责,那样子就需要使用组合模式了,这会引起类间耦合过重、类的数量增加等问题,额外的增加程序的复杂度。
单一职责有什么好处呢?
- 类的复杂性降低了,实现某个职责都有清晰明确的定义。
- 可读性提高了,复杂性降低,可读性自然降低了。
- 可维护性提高,可读性提高了,自然会更好维护。
- 变更引起的风险降低了,程度的变化是必不可少的,但如果单一职责黄划分得好的话,一个接口修改只会影响其实现类的变化,而不会影响其它接口。这对系统的扩展性、可维护性有很大的帮助。
这里有个问题需要说明一下,就是说职责这个东西,是很难区分的,像上面的我们把电话的功能都写在了一个接口上,也是没有问题的,实际大多数情况下我们也是这样设计的,因为我们在实际开发中需要考虑很多方面的因素,以及收益成本率。但是单从学究的层面上,这样的设计是有问题的,因为两个可能引起接口变化的因素,被放到了一个接口里,这为以后的变化带来了风险。这里的风险指的就是如果一个变化带来的结果是调用者不管是调用协议管理部分,还是数据传递部分,都需要变更,而分为两个接口后,只对各自的实现才需要变更。
注意
单一职责原则提出了一个编写程序的标准,用职责和变化原因来衡量接口或类的设计是否优良,但是职责和变化原因都是不可度量的因项目而异,因环境而异。
对于接口,我们在设计的时候尽量做到单一职责,但对于类我们就需要进行多方考虑了,如果生搬硬套单一职责只会引起类的剧增,增加系统的复杂性,本来是一个类可以实现的,却非要使用两个类分别实现接口,然后再通过组合方式耦合在一起,这样子做是得不偿失的。
单一职责在方法的应用
单一职责适用于接口、类,同样的,它也适用于方法。一个方法尽量只做一件事情。比如说我们需要修改用户名、密码、联系方式。我们不要把这三者都写到修改用户信息一个方法中去。类图为: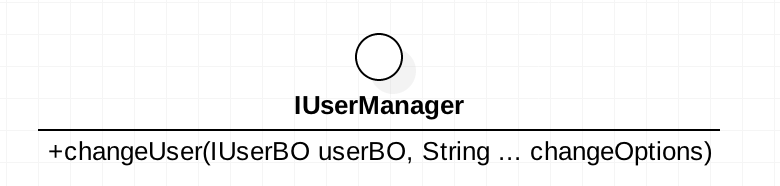 这里我们定义了一个
这里我们定义了一个changedUser的方法,根据传递的类型不同,把可变参数changeOptions修改到userBO这个业务对象上去,然后再调用持久层的方法保存到数据库。这样做使得这个方法做了太多的事情,完全没有遵从单一职责的原则。正确的做法为:  通过单一职责的改造,每个方法只完成一件事情,只有一个原因会引起该方法的变化。职责非常清晰明确,不仅开发简单,而且日后的维护也更加容易。
通过单一职责的改造,每个方法只完成一件事情,只有一个原因会引起该方法的变化。职责非常清晰明确,不仅开发简单,而且日后的维护也更加容易。
2.里氏替换原则
面向对象的三大特点:继承、多态、封装。而里氏替换原则就是依赖于继承和多态这两大特性的。里氏替换原则简单点说就是只要父类能出现的地方子类就可以出现,而且替换为子类也不会产生任何错误或者异常,使用者可能根本就不知道是父类或者子类,但是反过来是不行的,也就是有子类出现的地方,父类未必就能适应。
我们一般在系统设计时,经常会定义接口或者抽象类,然后来实现相应编码。调用者则直接传入接口或者抽象类,其实这里就是使用到了里氏替换的原则。我们在网络请求类中接收一个处理网络请求的工具类,这个工具类由两种实现方式。我们先来看一下类图: 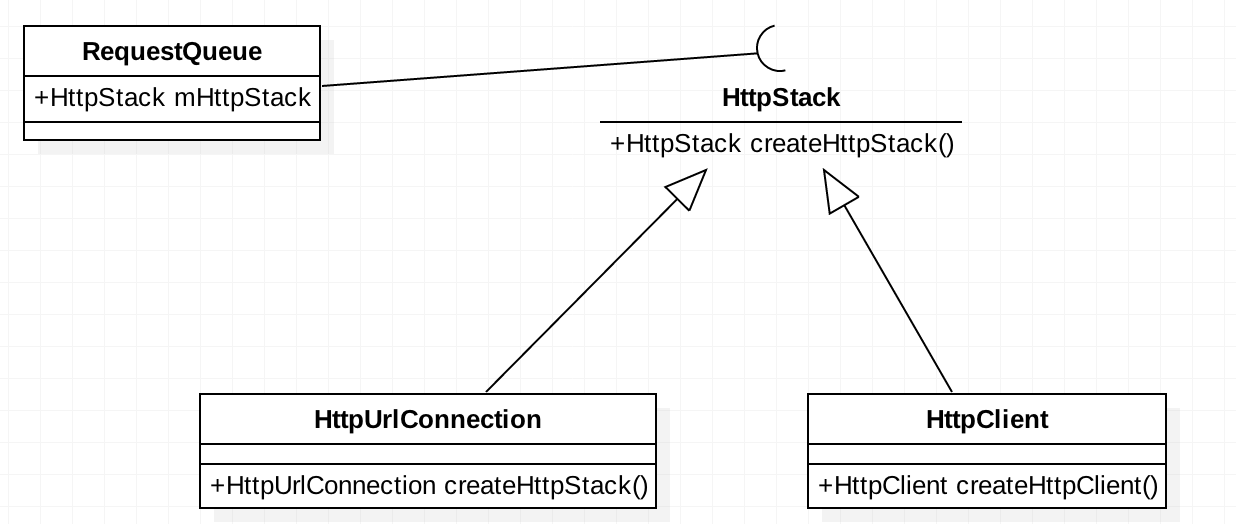 这里的
这里的RequestQueue依赖于HttpStack接口,而HttpStack有两个实现,也就是说这里任意使用一个实现都可以传入到RequestQueue中去,然后完成网络请求的功能。这里我们来看一看伪代码. 这个是执行网络请求的类,依赖于
这个是执行网络请求的类,依赖于HttpStack。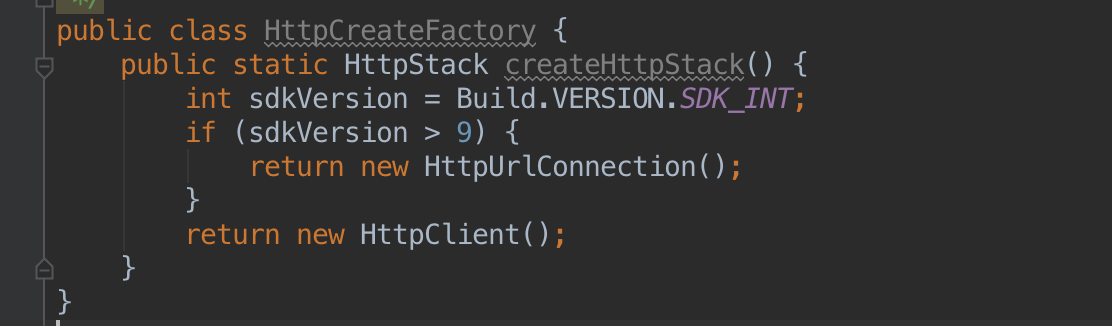 这个是创建
这个是创建HttpStack接口的实现类,根据不同的API版本创建不同的实现类。
我们再来以一个CS例子来说明一下这个原则吧。以下是相应的类图: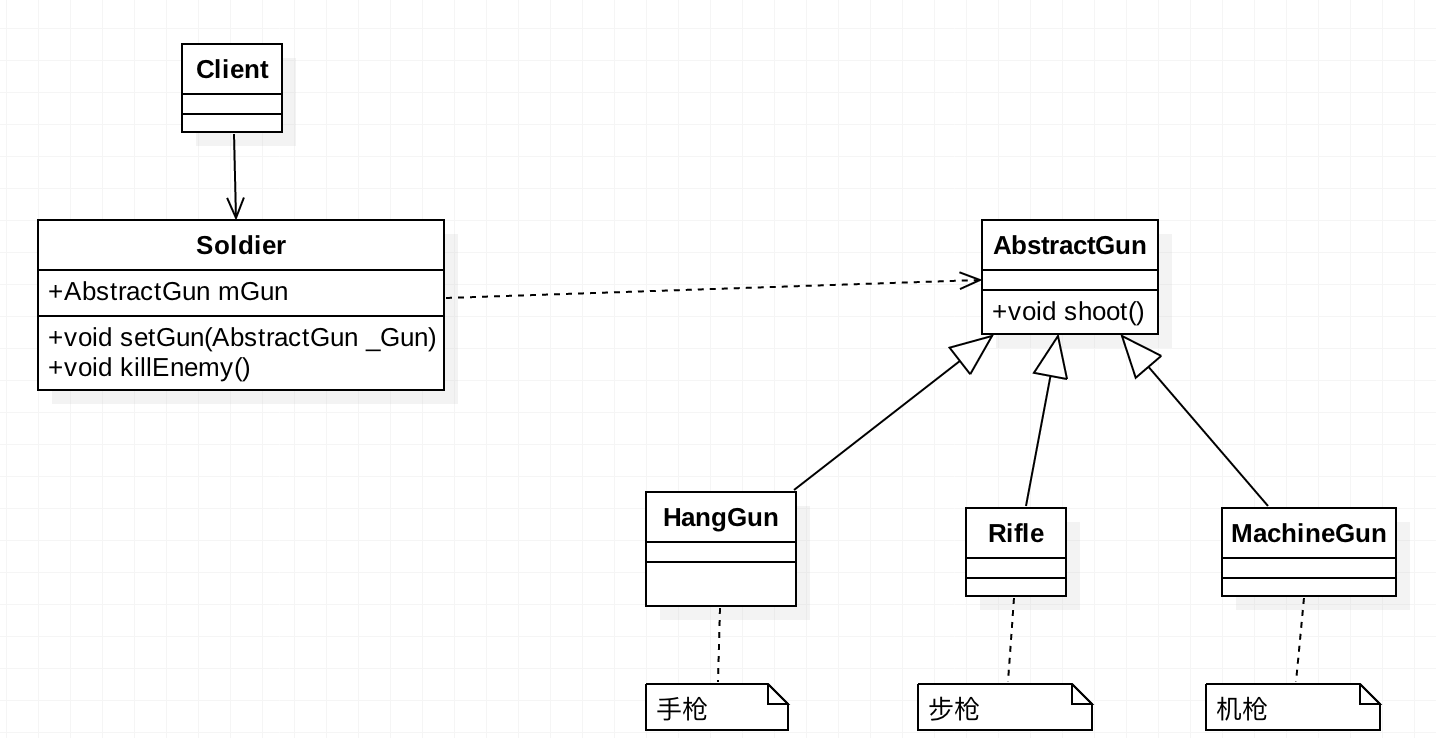 枪的主要职责是射击,如何射击各个具体的子类中定义。士兵类中定义了一个方法
枪的主要职责是射击,如何射击各个具体的子类中定义。士兵类中定义了一个方法killEnemy,使用枪来杀敌人,但具体使用什么枪,这个要让调用者来决定。AbstractGun类的代码为:
public abstract class AbstractGun {
//使用枪来杀敌
public abstract void shoot();
}
相应的子类的代码为:
public class HangGun extends AbstractGun {
@Override
public void shoot() {
System.out.println("使用手枪来杀敌人...");
}
}
public class RifleGun extends AbstractGun {
@Override
public void shoot() {
System.out.println("使用步枪来杀敌人...");
}
}
public class MathineGun extends AbstractGun {
@Override
public void shoot() {
System.out.println("使用机枪来杀敌人...");
}
}
有了枪支之后,还需要有使用枪支的士兵:
public class Solider {
AbstractGun mGun;
public void setGun(AbstractGun gun) {
this.mGun = gun;
}
/**
* 杀敌
*/
public void killEnemy() {
System.out.println("士兵开始杀敌...");
mGun.shoot();
}
}
这里的士兵开始杀敌,但是使用什么枪需要通过setGun()来确认。最后就是我们的场景类client的代码了:
public class Client {
public static void main(String args) {
Solider sanmao = new Solider();
sanmao.setGun(new HangGun());//为三毛指定的枪是手枪
sanmao.killEnemy();
}
}
运行的结果为:
“士兵开始杀敌…”
“使用手枪来杀敌人…”
这里我们为士兵三毛指定的是手枪。我们也可以为三毛指定机枪,只需将setGun(new HangGun())改成setGun(new MathineGun())即可,在编写士兵类时根本来需要知道使用的具体是什么枪(子类),只要是枪就可以了(父类)。
注意
在类中调用其它类时,务必使用父类或者接口,如果不能使用父类或接口,则说明这个类的设计已违反LSP(里氏替换)原则了。
里氏替换原则的优点
- 代码共享,减少创建类的工程量,每个子类都拥有父类的方法和属性。
- 提高代码的重用性。
- 提高代码的可扩展性。我们可以使用很低的成本增加一个新的实现,而调用者全然不知。
- 提高产品或项目的开放性。
这里的开放性,我们以上面网络请求的例子来说明一下。上面我们使用了两个工具类来完成Http网络请求的操作,但是如果我们这时需要使用okHttp这个工具类来实现网络请求呢?我们只需要使用okHttp来实现我们的HttpStack。在创建RequestQueue时,将其对象传入即可,而RequestQueue是不知道我们到底传的是哪个工具类的,事实上也不需要知道。这样子我们非常方便的就进行了扩展。
里氏替换原则的缺点
- 继承是侵入性的,只要继承,就必须拥有父类的方法和属性。
- 降低代码的灵活性,子类必须拥有父类的属性和方法,让子类的自由世界多了一份约束。
- 增加了耦合性,当父类的常量、变量和方法被修改时,必须要考虑子类的修改,如果在缺乏规范的环境下,这种修改势必会带来灾难,我们可能需要重构大面积的代码。
3.依赖倒置原则
依赖倒置原则的几个关键点为:
- 高层模块不能依赖于低层模块,两者都应该依赖抽象。
- 抽象不应该依赖细节。
- 细节应该依赖抽象。
这里需要怎么理解呢?高层模块和低层模块容易理解,每一个逻辑的实现都是由原子逻辑组成的,不可分割的原子逻辑就是低层模块。原子逻辑再组装的就称为高层模块。那什么是抽象呢?抽象在Java中表示为接口或者抽象类,它的特点是不可被实例化。什么又是细节呢?细节就是实现或者继承抽象类的子类,它们可以被实例化。依赖倒置原则在Java的体现为:
- 模块间的依赖通过抽象发生,实现类不直接发生依赖关系,其依赖关系依赖于接口或抽象类产生。
- 接口或抽象类不能依赖于实现类。
- 实现类依赖接口或抽象类。
依赖倒置原则可以通过一名话来定义:
面向接口编程(OOD)
在里氏替换原则中的第一个例子,我们的RequestQueue依赖中请求工具类使用的是接口,而不是具体的实现类,这就是典型的依赖倒置原则的体现。如果我们依赖具体的HttpUrlConnection类,那么HttpClient就无法传入,除非HttpClient继承自HttpUrlConnection类,但这显然不符合继承的特征,因为它们两者属于兄弟关系。
依赖倒置原则的优点
采用依赖倒置原则可以减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
这里我们通过反证法来证明不使用依赖倒置原则也可以减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
我们以一个会开车的司机为例来说明一下”不使用依赖倒置原则也可以减少类间的耦合性,提高系统稳定性”?先上类图: 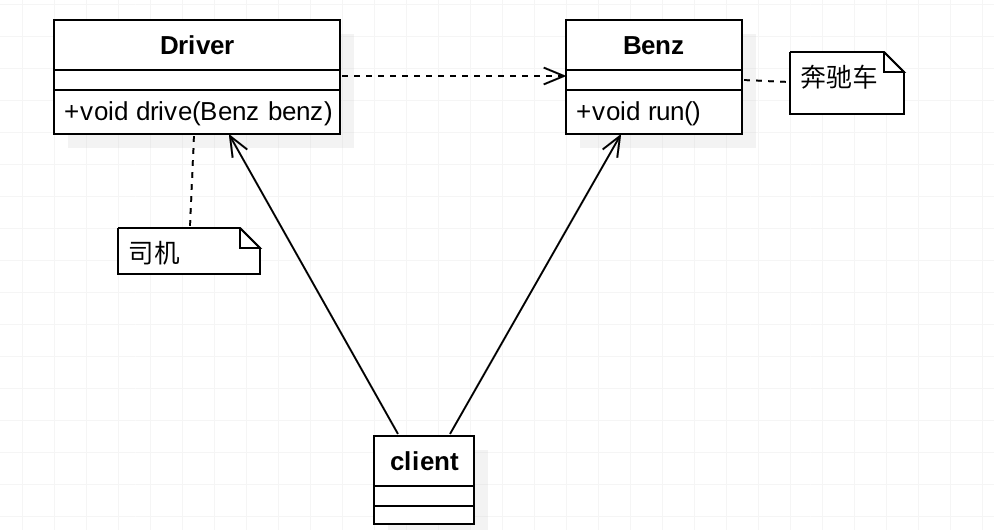
奔驰车提供一个run方法来开动奔驰车,代码如下:
public class Benz {
public void run() {
System.out.println("奔驰车开动了...");
}
}
有了车,我们就需要司机来开动这辆车,司机使用drive()方法来调用奔驰车的run()方法开动奔驰车,代码如下:
public class Driver {
//司机的主要职责是驾驶汽车
public void drive(Benz benz) {
benz.run();
}
}
有车,有司机后,我们就在场景类client创建相应的对象,让司机把车开动起来,代码如下:
public class Client {
public static void main(String args) {
Driver sanmao = new Driver();
sanmao.drive(new Benz());
}
}
通过上面的代码,完成了司机开动奔驰车的场景,到目前为此,是完全没有问题的。但是需求是一直在变化的,这时,奔驰车出故障了,送去维修了,这时需要司机来开宝马车。
public class Baoma {
public void run() {
System.out.println("宝马车开动起来了...");
}
}
那么问题来了,司机不会开宝马车。什么情况?拿一C照的同学只会开奔驰车,不会开宝马车??在现在生活中都是什么车都会开的,而程序是对现实世界的抽象,我们的设计出现了问题,把司机和奔驰车耦合在一起了。我们不可能再为宝马车再单独创建一个司机类来开宝马车吧。这样子,系统的稳定性太低了。而且被依赖者的变更居然需要依赖者来承担修改的成本,这个是很不合理的。所以,这里证明了“不使用依赖倒置原则可以减少系统的耦合性,增加系统的稳定性”是不成立的。
注意
设计是否具备稳定性,只要适当的“松松土”,观察“设计的蓝图”是否还可以茁壮成长就可以得出结论。稳定性较高的设计,在周围环境频繁变化的时候,依然不需要被改变。
接下来我们再说证明一下”不使用依赖倒置原则可以减少并行开发的风险”。
什么是并行开发的风险?并行开发的风险最主要是风险扩散,本来只是一段程序的错误或异常,而导致一个功能,一个模块,甚至到最后毁坏一个项目。为什么并行开发有这样子的风险呢?一个团队10个人,甲开发汽车模块,乙开发司机模块…如果甲还没有开发完汽车模块,那么乙就没法完全地编写代码,缺少汽车类,乙的功能模块根本无法编译通过,在这种不使用依赖倒置原则进行开发的环境中,所有的开发工作都是单线程开发。很明显不符合并行开发的要求。
根据以上证明:如果不使用依赖倒置原则,就会增加对象之间的耦合性,降低系统的稳定性,增加并行开发引起的风险,降低代码的可读性和可维护性。
接下来我们引入依赖倒置原则来对其进行改造。类图如下: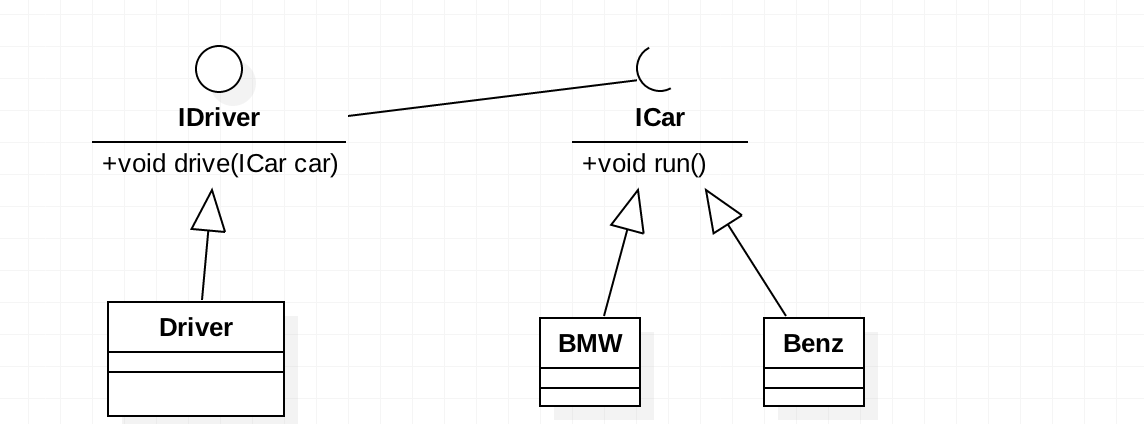 建立了两个接口,
建立了两个接口,IDriver和ICar,司机接口和汽车接口。司机的主要职责是开车,所以必然实现driver()方法,代码如下:
public interface IDriver {
void driver(ICar car);
}
接口只是一种规范,也就是一个抽象的东西,具体的实现由其实现类来完成,我们再来看看其实现类,代码如下:
public class Driver implements IDriver {
//这里通过依赖其抽象来脱离具体的细节
@Override
public void driver(ICar car) {
car.run();
}
}
这里使用依赖倒置原则依赖其接口,隔离了具体的实现细节。我们再来看看ICar和其两个实现类的代码:
public interface ICar {
//通过此方法开动汽车
void run();
}
public class Benz implements ICar{
@Override
public void run() {
System.out.println("奔驰车开动了...");
}
}
public class BMW implements ICar {
@Override
public void run() {
System.out.println("宝马车开动起来了...");
}
}
高层模块不能依赖于低层模块,而就当依赖其抽象,这里也就是接口。而我们的Client属于高层模块,因为其是多个逻辑的组合而非原子逻辑。下面是其代码实现:
public class Client {
public static void main(String args) {
IDriver sanmao = new Driver();
ICar benz = new Benz();
sanmao.driver(car);
}
}
Client是高层业务逻辑,它对低层模块的依赖都建立在抽象上,sanmao的表面类型为IDriver,benz的表面类型为ICar.也许你要问,在这个高层模块中也调用到了低层模块,比如:new Driver()和new Benz()等,确实如此,sanmao的表面类型是IDriver,是一个接口,是抽象的,非实例化的,在其后的操作中,sanmao都是以其IDriver类型进行操作,屏幕了细节对抽象的影响。
在新增加低层模块时,只修改了业务场景类,也就是高层模块,对其他低层模块如Driver类不需要做任何的修改,业务就可以运行,把变更引起的风险扩散降到最低。
注意
在
Java中,只要定义了变量,就必然要定义其类型,一个变量有两种类型:表面类型和实际类型。表面类型就是定义的时候赋予的类型,实现类型就是对象的类型。在上面sanmao这个对象中,表示类型是IDriver,而实际类型为Driver.
其实依赖倒置问题说白了就是解决依赖的问题,我们常见的依赖主要有三种方式:
- 构造函数依赖
- 方法依赖
- 接口声明依赖
1.构造函数依赖
在类中通过构造函数声明被依赖对象,这种方式被称为构造函数注入。我们通过此种依赖方式,将IDriver和Driver来进行改造,代码如下:
public interface IDriver {
void driver();
}
public class Driver implements IDriver {
private ICar mCar;
//通过注入依赖对象
public Driver(ICar car) {
mCar = car;
}
@Override
public void driver() {
mCar.run();
}
}
2.方法依赖注入
在类中通过Setter方法来声明被依赖对象,这种方法被称为方法注入。同样的我们还是将IDriver和Driver来进行改造,这里IDriver接口一样,就不贴了,代码如下:
public class Driver implements IDriver {
private ICar mCar;
@Override
public void driver() {
if (mCar != null)
mCar.run();
}
public void setCar(ICar car) {
this.mCar = car;
}
}
3.接口声明依赖
这种方式就和上面的例子是一样的了。
public interface IDriver {
void driver(ICar car);
}
最佳实践
依赖倒置原则的本质就是通过抽象(接口或者抽象类)使各个类或者模块实现彼此独立,互不影响,实现模块间的松耦合。我们在项目中可以遵照以下几个规则:
- 每个类尽量都有接口或抽象类,或者两者都具备。
- 变量的表面类型尽量是接口或者是抽象类。
- 任何类都不应该从具体类派生
- 尽量不要覆写基类非抽象方法
- 结合里氏替换原则使用
4.接口隔离原则
接口隔离原则指的就是客户端不就依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。根据接口隔离原则,当一个接口太大时,我们需要将它分割成一些更细小的接口,使用该接口的客户端仅需知道与之相关的方法即可。
这里我们可以把这两个定义概括为一句话:建立单一接口,不要建立臃肿庞大的接口。再通俗点讲:接口尽量细化,同时接口中的方法尽量少。看到这里大家可能会把接口隔离原则与单一职责原则进行比较,觉得这两个不是一样的么?其实不然,两个原则的关注的角度是不一样的.单一职责注重的是职责,这是业务逻辑的划分,而接口隔离原则要求接口的方法尽量少。
比如:一个接口的职责可能有10个方法,也就是说10个方法都是为了完成同一个职责,并且提供给多个模块访问,各个模块按照相应的约束进行访问,按照单一职责原则来说是被允许的,但是执照接口隔离原则来说是不被允许的,因为接口隔离原则要求尽量使用多个专门的接口。专门的接口?什么意思呢?这里所说的意思是为每个模块提供单独的接口,也就是有几个模块需要使用,就对应的提供单独的相应接口,而不是建立一个臃肿庞大的接口,让所有模块来访问。
我们以星探和美女的例子来说明一下吧。大家都知道星探的工作任务之一就是发现美女,而一般我们对美女的定义必须具备:面貌、身材和气质。只是每个人对这三种条件的排列顺序不同罢了。我们用类图的形式来说明一下星探找美女的过程。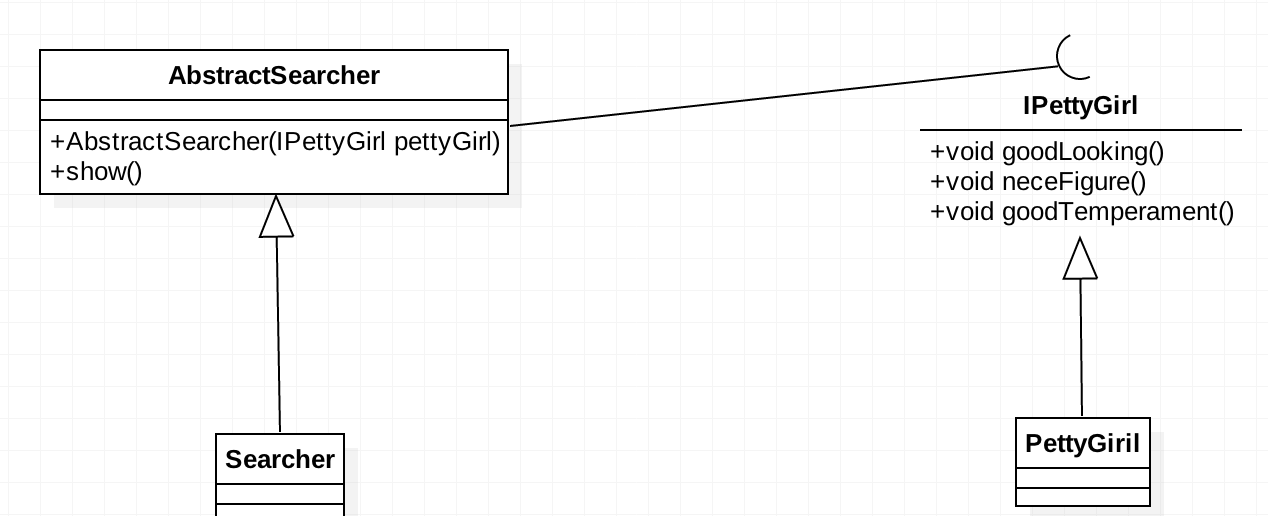 定义了一个
定义了一个IPettyGirl声明美女应该有的特征,然后定义一个抽象类AbstractSearcher,其作用是发现美女并将其信息显示。我们来看一下IPettyGirl接口的代码吧:
public interface IPettyGirl {
void goodLooking(); //好的面貌
void niceFigure(); //好的身材
void goodTemperament(); //好的气质
}
再来看看IPettyGirl的实现类:代码如下:
public class PettyGirl implements IPettyGirl {
private String mName;
public PettyGirl(String name) {
mName = name;
}
@Override
public void goodLooking() {
System.out.println(mName+",--脸蛋很漂亮...");
}
@Override
public void niceFigure() {
System.out.println(mName+",--身材好...");
}
@Override
public void goodTemperament() {
System.out.println(mName+",--有气质...");
}
}
通过上面三个方法,我们就把美女的标准定义下来了。接下来看看星探抽象类AbstractSearcher的代码:
public abstract class AstractSearcher {
protected IPettyGirl mPettyGirl;
public AstractSearcher(IPettyGirl girl) {
this.mPettyGirl = girl;
}
//找到美女,将美女信息列出来
public abstract void show();
}
实现类Searcher的代码:
public class Searcher extends AstractSearcher {
public Searcher(IPettyGirl girl) {
super(girl);
}
@Override
public void show() {
System.out.println("美女" + super.mPettyGirl + "的信息如下:");
super.mPettyGirl.goodLooking();
super.mPettyGirl.niceFigure();
super.mPettyGirl.goodTemperament();
}
}
星探和美女都有了,最后需要使用场景类Client来将两者串起来。代码如下:
public class Client {
public static void main(String args) {
IPettyGirl pettyGirl = new PettyGirl("小雪");
AstractSearcher searcher = new Searcher(pettyGirl);
searcher.show();
}
}
执行的结果如下:
美女小雪的信息如下:
小雪,–脸蛋很漂亮…
小雪,–身材好…
小雪,–有气质…
到这里星探找美女的程序开发完毕,运行也没问题。但这里我们来讨论一下这里的接口设计是否存在问题,是否可以对接口进行优化,答案是可以的。因为美女这类事物是可能通过时间和人的改变而发生发生变化的,比如,当出现一个脸蛋一般、身材一般但是却很有气质的女孩出现时,我相信大多数人都会把这样子的女孩称为美女,大家的审美提升了,就出现了气质型美女,但是我们的接口里定义了美女必须是三者都具备,按照这个标准,气质型美女就不能算美女了,那怎么办?重新扩展一个美女实现类,只实现greatTemperament()方法,其他两个方法空置,什么都不写,不是可以么?答案是不行的,星探AbstractSearcher依赖的是IPettyGirl接口,它是依赖三个方法来判断是不是美女的,而你现在只实现了一个方法,其它两个方法留空,除非再修改星探方法判断美女的规则,不然,上面的打印少了两条,星探是没办法进行判断的。
分析到这里,我们发现IPettyGirl接口的设计存在缺陷,接口的设计庞大了,容纳了一些可变的因素,根据接口隔离原则,星探AbstractSearcher依赖的应该是具有部分特质的美女接口,而我们把所有特质都封装到了一个接口。好了,问题找到了,我们要把接口进行拆分,将其分为两部分,其类图如下: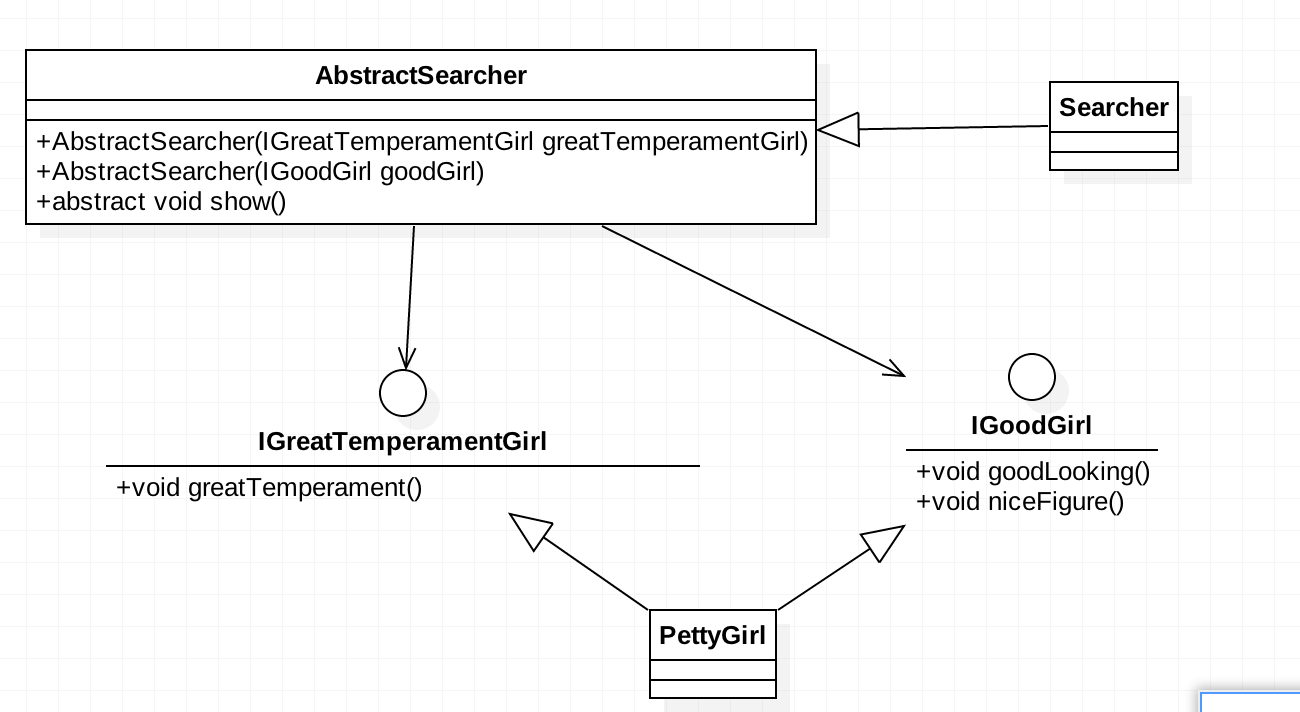 这里我们把
这里我们把IPettyGirl接口拆分为两个接口,一种是外形的美女IGoodGirl,这类美女脸蛋和身材极棒,但是没有审美素质,比如不讲文明;另外一种是气质美的美女IGreatTemperamentGirl,谈吐和修养都非常高。通过这样的拆分,灵活性提高了,可维护性增加了,不管以后是要气质美女还是外形美女都可以通过PettyGirl来进行定义。两种美女的接口定义为:
//外形美女
public interface IGoodGirl {
void goodLooking();
void niceFigure();
}
//气质美女
public interface IGreatTemperamentGirl {
void greatTemperament();
}
这两个接口的实现类PettyGirl的代码为:
public class PettyGirl implements IGreatTemperamentGirl, IGoodGirl {
private String mName;
public PettyGirl(String name) {
mName = name;
}
@Override
public void goodLooking() {
System.out.println(mName + ",--脸蛋很漂亮...");
}
@Override
public void niceFigure() {
System.out.println(mName + ",--身材好...");
}
@Override
public void greatTemperament() {
System.out.println(mName + ",--有气质...");
}
}
这里得说明一下,接口的稳定是相对的,如果你哪天又觉得需要把脸蛋和身材分成两个接口,这里的IGoodGirl接口还是需要更改的,但是设计是有限度的,不能无限度的考虑未来的变化情况,否则就会陷入设计泥潭而无法自拨。
接口隔离原则的四层含义:
1. 接口要尽量小
这是接口隔离原则的核心,不出现臃肿庞大的接口,但是小也是有限度的,首先就是不能违反单一职责原则,这里所说的意思是:单一职责已经是最小的业务单位了,再拆分下去,业务逻辑就会出现问题。那么是拆还是不拆呢?根据接口隔离原则拆分接口时,首先必须满足单一职责原则。
2.接口要高内聚
什么是高内聚呢?高内聚就是提高接口、类、模块的处理能力,减少对外的交互。要求在接口中尽量少公布public方法,接口对外的承诺,越少对开发越有利,变更的风险也就越少,同时也有利于降低成本。
3.定制服务
定制服务就是针对单个个体提供优良的服务。我们在做系统设计时也需要考虑对系统之间或者模块之间的接口采用定制服务,定制服务有一个要求:只提供访问者需要的方法。
比如我们开发了一个图书管理系统,其中有一个接口供管理员查询书籍。类图: 在接口里我们定义了多个方法,如按作者、按标题、按出版社、及复杂搜索等方式。这里我们根据了权限的不同,有些接口是没有返回的。突然有一天,服务器的性能下降,然后继续跟踪下去,发现很大部分的查询都是从公网发起的,根据分析后发现:提供给公网的查询接口和内部管理人员使用的接口是一样的,那么问题来了,这里有一个
在接口里我们定义了多个方法,如按作者、按标题、按出版社、及复杂搜索等方式。这里我们根据了权限的不同,有些接口是没有返回的。突然有一天,服务器的性能下降,然后继续跟踪下去,发现很大部分的查询都是从公网发起的,根据分析后发现:提供给公网的查询接口和内部管理人员使用的接口是一样的,那么问题来了,这里有一个searchByComplex是只提供给内部管理人员查询全部书籍用的,虽说,根据权限的不同,外部人员访问了 此接口也是返回为空的,但是这个接口其实是有运行的,只是最后做了屏蔽而已。根据这个情况,我们来重新设计一下接口,为普通用户和管理员专门定制接口。这里我们将上面的接口分为了两个,分别为ISimpleSearcher和IComplexSearcher两个接口,下面是相应的类图: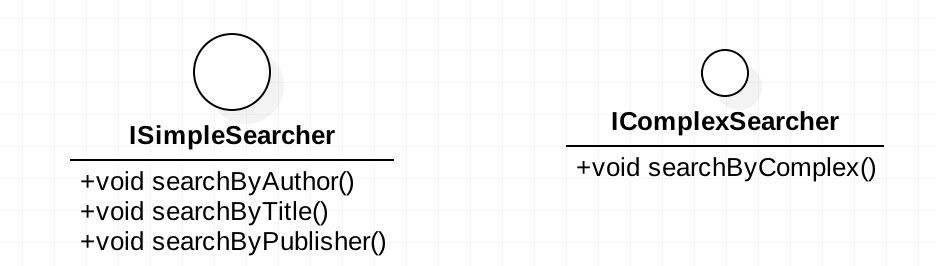 提供给管理人员的实现类同时实现了
提供给管理人员的实现类同时实现了ISimpleSearcher和IComplexSearcher两个接口,而只将ISimpleSearcher提供给外网,用作简单的查询,以减少可能引起的风险。
4.接口的设计是有限度的
接口的设计粒度越小,系统越灵活,这是不争是事实,但灵活的同时也带来了复杂度的增加,开发难度的增加,这并不是我们想看到的,这里的接口设计应该有一个度,但这个度也没有明确的界定,需要根据开发者的开发环境,经验等来作判断。
接口隔离原则最佳实践
- 一个接口只服务于一个子模块或者业务逻辑
- 通过业务逻辑压缩接口中的
public方法,接口时常去回顾,尽量要让接口中暴露的方法都是必须暴露的,而不是肥嘟嘟的一大堆方法- 已经被污染了的接口,尽量去修改,若变更的风险较大,则使用适配器模式去转化处理。
- 了解环境,拒绝盲从。根据具体的产品,具体的环境适时的使用相应的原则,万不可按步就搬。
- 以满足
单一职责原则为前提条件。
5.迪米特原则
迪米特原则也称为最少知道原则,虽然名字不同,但是描述的是同一个规则,用一句话来说明:一个对象应该对其他对象有最少的了解。通俗地讲,一个类应该对与自己需要耦合或者调用的类知道得最少,你(被耦合或被调用的类)的内部有多复杂,那是你的事,我就只需要知道你提供的public方法,我就调用这么多,其它的我一律不管。
5.1 迪米特原则的要求
1.只和朋友交流
迪米特原则的英文解析是:Only talk to your immedate friends(只和你直接的朋友通信)。什么叫直接的朋友呢?每个对象都会与其它对象有耦合关系,这种耦合关系就称为朋友关系。这种关系的类型有:组合、聚合、依赖等。
举个例子吧:一群学生在操场上体育课,开始点名,老师命令体育委员清点一下班上女生的个数。我们使用类图来模拟一下: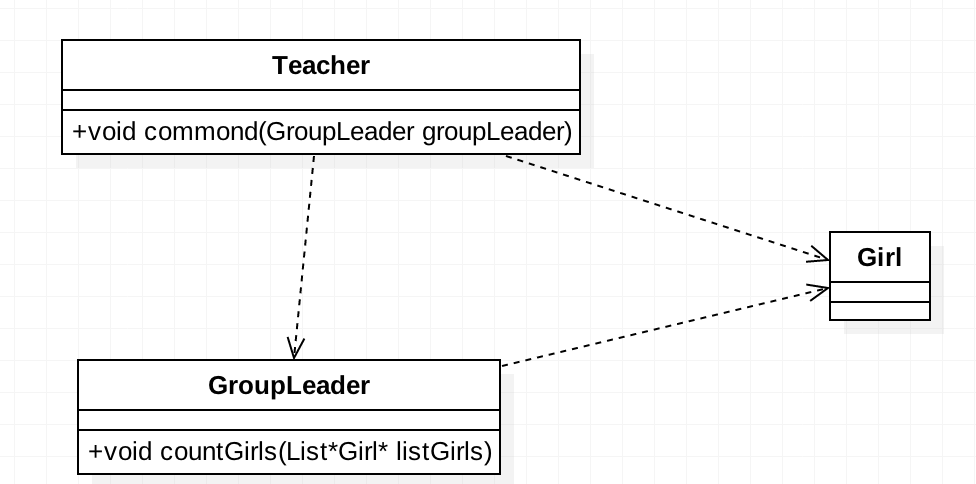
Teacher类的commond方法负责发送命令给体育委员,命令他清点女生。实现代码如下:
public class Teacher {
public void commond(GroupLeader groupLeader) {
//这里初始化女生
List<Girl> mGrils = new ArrayList<>();
for (int x = 0; x < 20; x++) {
mGrils.add(new Girl());
}
groupLeader.countGirls(mGrils);
}
}
老师类只有一个方法,这个方法里先初始化女生,然后命令体育委员去清点女生。接下来是体育委员类:
public class GroupLeader {
public void countGirls(List<Girl> mGrils) {
System.out.println("班上的女生人数 为:"+mGrils.size());
}
}
老师和体育委员类都要依赖于女生类,而女生类不需要做任何的事情,所以直接创建一个空类:
public class Girl {
}
示例中所有的角色已经定义完毕,接下来就需要场景类client来跑跑跑了。
public class Client {
public static void main(String args) {
Teacher teacher = new Teacher();
teacher.commond(new GroupLeader());
}
}
运行的结果如下所示:
班上的女生人数 为:20
接下来我们来考虑一个这个程序有什么问题,首先确定Teacher有几个朋友,它仅有一个朋友,groupLeader。为什么Girl不是它的朋友呢?朋友类的定义是通过注入添加的依赖才是朋友类,而出现在方法内部的类不属于朋友类。而这里的Girl是在Commond()方法内部,所以不属于朋友类。那么问题来了,既然不是朋友类,怎么能进行交流呢?迪米特原则告诉我们一个类只能和朋友类进行交流。这样就破坏了Teacher的健壮性。方法是类的一个行为,类竟然不知道自己的行为与其他类产生依赖关系,这是不被允许的,严重违反了迪米特原则。
问题发现了,那我们来修改一下吧。先来看类图的修改: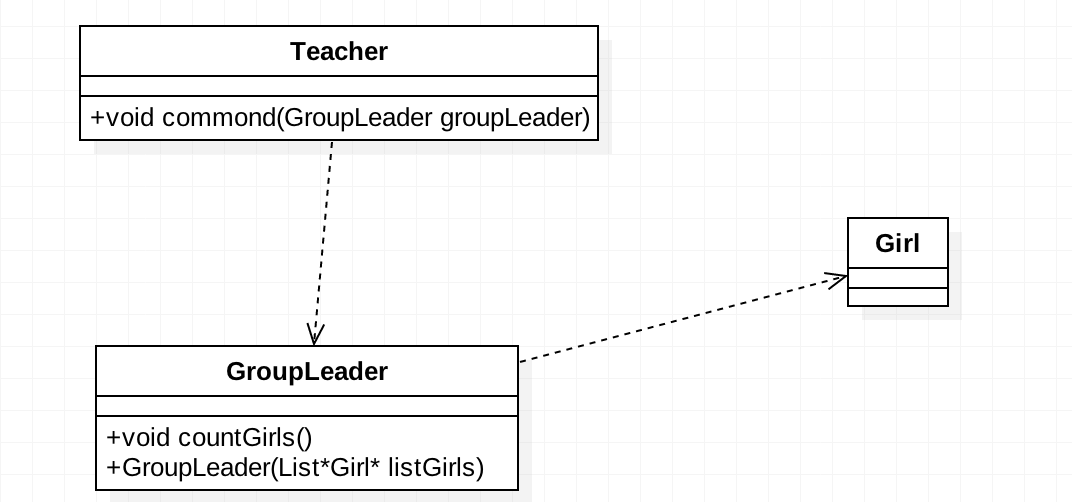 在类中去掉
在类中去掉Teacher对Girl的依赖关系,修改后的Teacher类代码如下:
public class Teacher {
public void commond(GroupLeader groupLeader) {
groupLeader.countGirls();
}
}
这里只和它的朋友类交流,下面的GroupLeader类:
public class GroupLeader {
private List<Girl> mGirls;
GroupLeader(List<Girl> listGirls) {
mGirls = listGirls;
}
public void countGirls() {
System.out.println("班上的女生人数为:" + mGirls.size());
}
}
在GroupLeader类中通过构造方法传递了依赖关系,也就是GroupLeader的朋友类为Girl类。最后来看看场景类的修改:
public class Client {
public static void main(String args) {
Teacher teacher = new Teacher();
List<Girl> mGrils = new ArrayList<>();
for (int x = 0; x < 20; x++) {
mGrils.add(new Girl());
}
teacher.commond(new GroupLeader(mGrils));
}
}
运行的结果如下:
班上的女生人数为:20
对程序进行简单的修改,将对女生的初始化放到了场景类,同时在GroupLeader中增加了对Girl的注入,避开了Teacher类对陌生类Girl类的访问,降低了系统的耦合性,提高了系统的健壮性。
注意
一个类只和朋友交流,类与类间的关系是建立在类间的,而不是方法间,因此一个方法尽量不引入一个类中不存在的对象。
2.朋友间也是有距离的
这里所说的是再好的朋友也要保持距离,不能无话不说,无所不知。对朋友关系描述最贴切的故事是:两只刺猬取暖,太远取不到暖,太近会刺伤对方。我们在安装软件的时候经常需要第一步做什么,第二步执行什么,第三步输入什么…这里我们拿安装软件的例子来说明一下朋友间也是有距离的。首先上类图: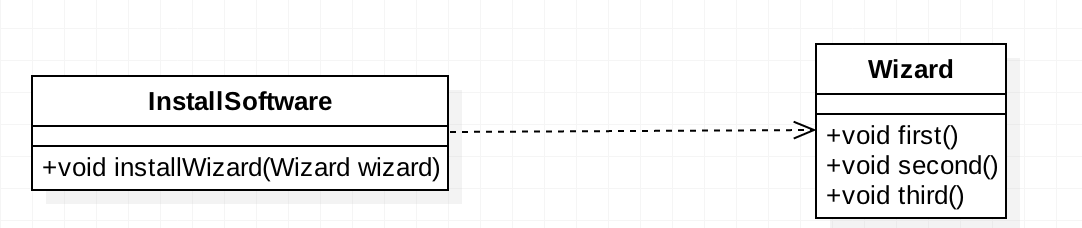 我们来看一下
我们来看一下Wizard的代码实现:
public class Wizard {
private Random mRandom = new Random(System.currentTimeMillis());
public int first() {
System.out.println("第一个方法执行了...");
return mRandom.nextInt(100);
}
public int second() {
System.out.println("第二个方法执行了...");
return mRandom.nextInt(100);
}
public int third() {
System.out.println("第三个方法执行了...");
return mRandom.nextInt(100);
}
}
在Wizard中有三个方法,每个方法都完成相应的业务逻辑,我们这里以随机数返回值来说明代替业务执行后的返回结果。我们再来看看软件安装类的代码实现:
public class InstallSoftware {
public void installWizard(Wizard wizard) {
int first = wizard.first();
if (first > 50) {
int second = wizard.second();
if (second > 50) {
int third = wizard.third();
if (third > 50)
wizard.first();
}
}
}
}
相应的类定义完毕后,我们使用场景类来跑一跑:
public class Client {
public static void main(String args) {
InstallSoftware installSoftware = new InstallSoftware();
installSoftware.installWizard(new Wizard());
}
}
程序的实现非常简单,但是大家思考一下有没有发现什么问题呢?InstallSoftware和Wizard的关系太密切了,Wizard暴露太多的方法给InstallSoftware,两个类牢牢的耦合在一起了。试想一下,我们把Wizard中first里的返回值类型为boolean,就需要修改InstallSoftware,从而将修改的风险扩散了。还是那句老话,被依赖的类修改了,需要依赖者来承担修改的变化,谁干啊!知道问题之后,我们来对设计进行重构一下。类图如下: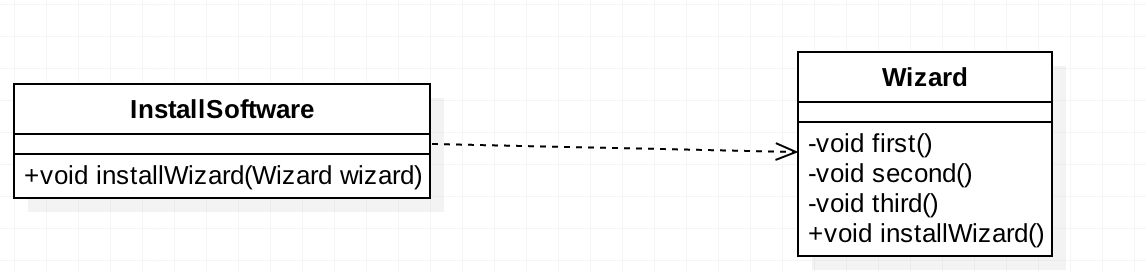 这里我们将
这里我们将Wizard中增加一个installWizard()将安装过程封装了,然后修改了三个方法的访问权限为private。修改后的代码为:
public class Wizard {
private Random mRandom = new Random(System.currentTimeMillis());
private int first() {
System.out.println("第一个方法执行了...");
return mRandom.nextInt(100);
}
private int second() {
System.out.println("第二个方法执行了...");
return mRandom.nextInt(100);
}
private int third() {
System.out.println("第三个方法执行了...");
return mRandom.nextInt(100);
}
public void installWizard() {
//将在InstallSoftware中的业务逻辑移过来了
int first = first();
if (first > 50) {
int second = second();
if (second > 50) {
int third = third();
if (third > 50)
first();
}
}
}
}
将三个安装步骤的访问权限设置为private,将InstallSoftware中的installWizard()方法过来了。通过重构后,Wizard类对外暴露的方法只有一个installWizard(),此时,即使first()的返回值改变了,也是会影响Wizard类,这显示了类的高内聚特性。 InstallSoftware类的代码如下:
public class InstallSoftware {
public void installWizard(Wizard wizard) {
wizard.installWizard();
}
}
场景类没有发生任何变化,还是和之前的一样。通过上面的重构,类间的耦合变弱了,由变更所导致的风险变小了。
一个类的public方法或属性越多,变更时带来的风险就越大,在开发时要尽量对使用public修辞的变量多思考,除非是非公开不可,不然,要尽量减少public的使用。
注意
迪米特原则要求类羞涩一点,尽量不要对外公布太多的public方法和非表态public变量。
3.是自已的就是自己的
在实际开发中经常会遇到一些方法,放在这个本类里可以,放在其他类也没问题,那应该怎样去权衡呢?有一个原则:如果一个方法放在本类中,既不增加类间的关系,又没有产生负面影响,那就放在本类里。
迪米特原则最佳实践
迪米特原则的核心观念就是类间的解耦,类间的复用率才可以提高。但是过分的使用该原则,可以会多出大量的中转或者跳转类,增加系统的复杂性,同时也为维护带来了难度。所以,在使用迪米特原则时,既要做到结构清晰,又要做到类的高内聚,低耦合。 在实际项目中,需要适度考虑这个原则,别为了套用原则而做项目。原则只是作为参考,使用前需要反复权衡利弊,切勿为了使用而使用。一定是为了解决相关问题才去使用。
6.开闭原则
开闭原则是Java中最基础的设计原则。遵从该原则,会使你的系统稳定而灵活。我们先来看看开闭原则主要说的是什么吧!
开闭原则主要说的是一个类、模块和函数应该对修改关闭,对扩展开放。
这里说的意思就是:软件实体应该通过扩展来拥抱变化,而不是直接的修改。软件的实体主要包括以下几部分:
- 项目或者软件产品中按照一定的逻辑规则划分的模块。
- 抽象和类。
- 方法。
一个项目最不会变的就是变化,所以我们要在设计系统时,适当的考虑到将来可能的变化,以提高项目的稳定性和灵活性。开闭原则告诉我们:尽量使用扩展的方式来完成变化,而不是通过修改已有代码。接下来我们通过一个书店卖书的例子来说明一下开闭原则吧,先上类图: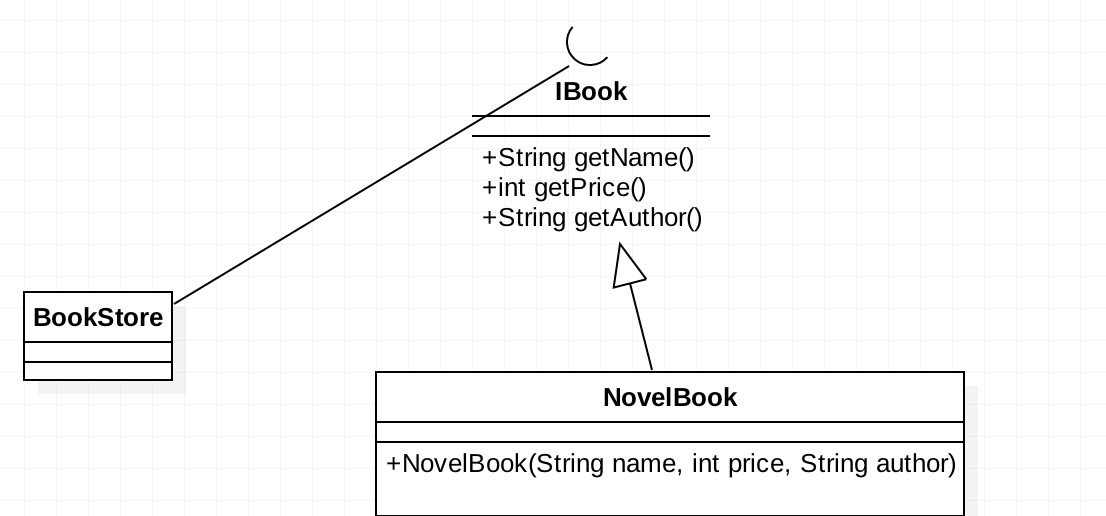 IBook有三个属性,分别是书名、价格、作者;
IBook有三个属性,分别是书名、价格、作者;NovelBook是一个具体的实现类,BookStore是书店。下面是相应的代码:
//接口类
public interface IBook {
String getName();
int getPrice();
String getAuthor();
}
public class NovelBook implements IBook {
private String name;
private int Price;
private String author;
public NovelBook(String name, int price, String author) {
this.name = name;
this.Price = price;
this.author = author;
}
@Override
public String getName() {
return this.name;
}
@Override
public int getPrice() {
return this.Price;
}
@Override
public String getAuthor() {
return this.author;
}
}
接下来就是书店类,这里需要造一些数据出来,这里有一个问题需要说明一下,我们把价格定义为int型其实是没有问题的,因为在非金融类项目中,一般取2位精度,通常的设计是在运算过程中扩大100倍,在需要展示时再缩小100倍,减少精度带来的误差。
public class BookStore {
public static final List<IBook> mBookList = new ArrayList<>();
static {
mBookList.add(new NovelBook("编程之美", 5500, "a君"));
mBookList.add(new NovelBook("设计模式", 7560, "b君"));
mBookList.add(new NovelBook("开发进阶", 4650, "c君"));
mBookList.add(new NovelBook("研磨设计", 3400, "d君"));
}
public static void main(String[] args) {
NumberFormat format = NumberFormat.getCurrencyInstance();
format.setMaximumFractionDigits(2);
System.out.println("--------下面展示的是书店卖出去的书籍---------");
for (IBook book : mBookList) {
System.out.println("当前书名为:" + book.getName() + ";价格为:" + format.format(book.getPrice()) + ";作者为:" + book.getAuthor());
}
}
}
运行结果如下:
——–下面展示的是书店卖出去的书籍———
当前书名为:编程之美;价格为55;作者为a君
当前书名为:设计模式;价格为75.6;作者为b君
当前书名为:开发进阶;价格为46.5;作者为c君
当前书名为:研磨设计;价格为34;作者为d君
好了,项目功能已经开发完成了,书籍正常销售出去,书店也盈利了。但随着互联网的兴起,网上大打价格战,线下自然也受到了牵连,为了能够生存下来,书店对书籍开始打折销售。所有40元以上的书9折销售,其它的一律8折。对于已经上线的项目,这就是一个变化的需求。那面对这种需求,我们大致有三种方式来实现:
1.修改接口
在接口中添加一个getOffPrice()打折的方法,让子类去实现。这样一来,接口需要被修改,实现类也需要被修改,还有依赖者也需要被修改。而接口作为一种规则,一种规范,是不应该经常发生变化的,所以,该方案否定。
2.修改实现类
第二种实现方式就是直接在实现类对getPrice()方法加条件。的确,这种方式可以比较好的解决这个问题。但这里有一个问题,就是如果这样修改之后,书籍的原来价格不见了,买书的人看不到原价而只能看到打折价,这样子会因为信息不对称而出现问题。所以,这个方案也不是最优的方法。
3.通过扩展实现变化
要怎么来进行扩展呢?我们创建一个新的类OffNovelBook,覆盖getPrice()方法,高层次模块改变其静态代码块中的依赖对象为OffNovelBook,这样修改也少,风险也小。我们来看下修改后的类图: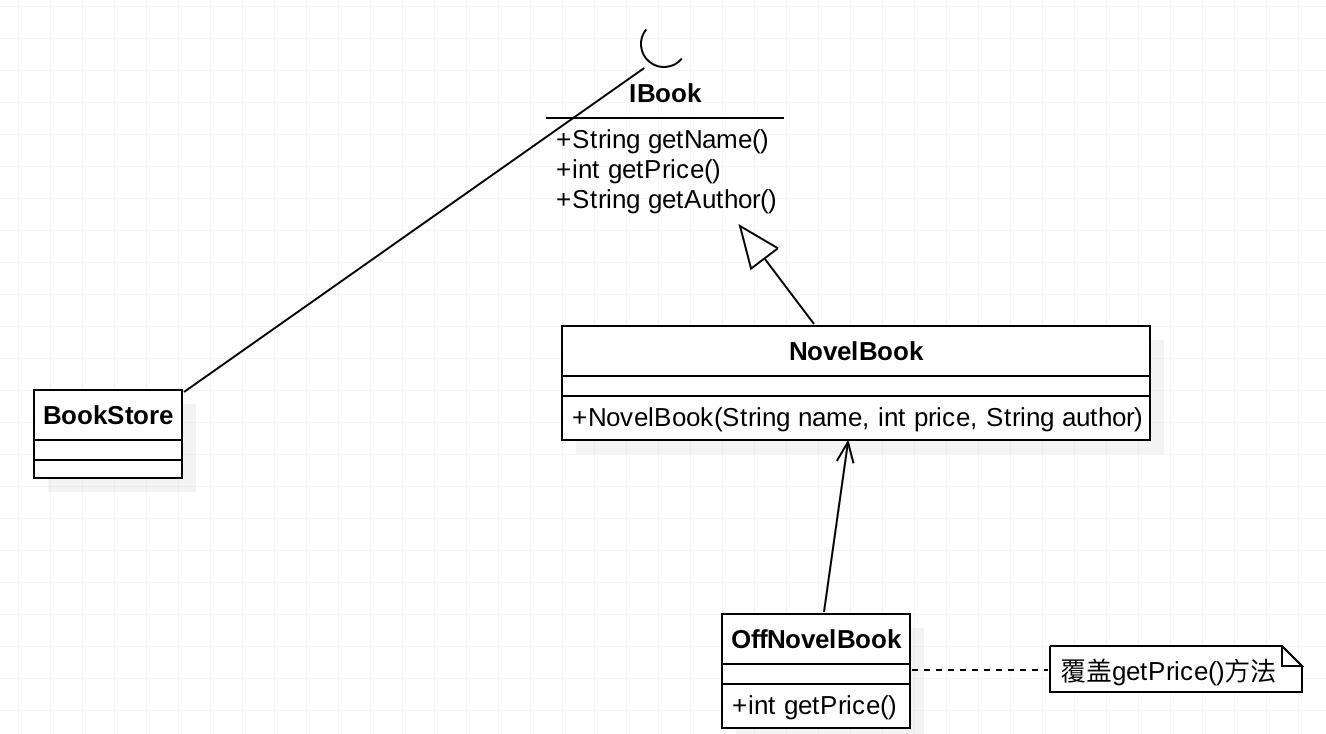 这里的
这里的OffNovelBook继承了NovelBook,并覆盖了getPrice()方法,不修改原有代码,而是做了扩展。OffNovelBook的代码如下:
public class OffNovelBook extends NovelBook {
public OffNovelBook(String name, int price, String author) {
super(name, price, author);
}
@Override
public int getPrice() {
int selfPrice = super.getPrice();
int offPrice = 0;
if (selfPrice > 40) {
offPrice = selfPrice * 90 / 100;
} else {
offPrice = selfPrice * 80 / 100;
}
//返回打折后的价格
return offPrice;
}
}
通过子类覆写了一个getPrice()方法,完成了新增的业务。BookStore作为高层模块依赖于子类OffNovelBook,所以代码中的相关依赖要改成OffNovelBook。修改代码如下:
public class BookStore {
public static final List<IBook> mBookList = new ArrayList<>();
static {
mBookList.add(new OffNovelBook("编程之美", 100, "a君"));
mBookList.add(new OffNovelBook("设计模式", 200, "b君"));
mBookList.add(new OffNovelBook("开发进阶", 120, "c君"));
mBookList.add(new OffNovelBook("研磨设计", 110, "d君"));
}
public static void main(String[] args) {
NumberFormat format = NumberFormat.getCurrencyInstance();
format.setMaximumFractionDigits(2);
System.out.println("--------下面展示的是书店卖出去的书籍---------");
for (IBook book : mBookList) {
System.out.println("当前书名为:" + book.getName() + ";价格为:" + book.getPrice() + ";作者为:" + book.getAuthor());
}
}
}
这里的结果和上面运行的一样。
这里可能大家有个疑问?就是你的业务逻辑还是修改了,你修改了static静态模块区域所依赖的对象。这部分确实个性了,该部分属于高层次的模块,在业务需求变更的前提下,高层模块是需要作出相应的改变已适应变化的,只是这个修改要尽量少,避免扩散变化的风险。
注意
开闭原则对扩展开放,对修改关闭,并不意味着不做任何的修改,低层模块的变更,必然要高层模块进行耦合,也就是进行相应的修改,不然,就是一个孤立的代码片段。
项目变化的三种类型
只变化逻辑,而不涉及其它模块。比如:一个方法里的算法是ab+c,这里变化后算法变成ab*c,像这样的一类变化,我们可以直接在原有类里进行修改。
由于变化,低层模块通过扩展来实现了变化,而依赖低层模块的高层模块由于耦合关系也需要跟着变化,上面的书的例子就说明了这个问题。
可见视图的变化也就是界面的变化,这种变化也是可以通过扩展来实现变化,但取决于原有设计的灵活性。
一个项目的路径是这样子的,开发、重构、测试、面世、运维,其中重构就是对原有的设计和代码进行修改,运维尽量减少去对代码进行直接的修改,保持代码的干净和稳定。
为什么要使用开闭原则呢?
在书店的例子中,增加了一个打折的需求,如果我们直接在
getPrice()方法里去进行修改来完成逻辑的变化,那就要修改测试类。如果是一个复杂的逻辑,其中写了很多的测试方法,直接进行修改的话,你的测试类就会被修改得面目全非。一般而言,我们一个类对应一个测试类,然后测试类中有很多的测试方法,想想在很多的测试方法中来进行修改是一件多么痛苦的事情。 在面向对象设计中,所有的逻辑都是由原子逻辑组成的,而不是一个类独立实现一个业务逻辑。只有这样的代码才能进行复用。粒度越小,可复用的可能性就越大。为什么要进行复用呢?避免同一段代码在项目的多个地方重复出现,如果其中逻辑需要修改,就需要重复修改多处的代码,而且很容易遗漏。所以在开发时,尽量将逻辑的粒度缩小,直到一个逻辑不可再分为止。
一个软件投产后,维护人员除了做日常的数据维护,还需要对程序进行扩展,维护人员乐意的做事情是对代码进行扩展,而不是修改。甭管原有的代码写得是多么优秀或者糟糕,让维护人员去读懂一段代码,并进行修改是一件非常痛苦的事情。
万物皆对象,有运动就有变化,有变化变要策略去应对,怎么快速应对?这就需要在设计之初考虑充分考虑到未来可能的变化,然后留
怎么使用开闭原则呢?
开闭原则是一个非常虚的原则,前面5个原则可以说是开闭原则的具体解释。但它并不局限于上面5个原则,它就像一个口号一样。那我们怎样把这个口号应用到工作中呢?
抽象是对现实事物的描述,它没有具体的实现。也就表示它有很多种可能性,可以跟随需求而变化。因些,通常使用接口或者抽象类来约束一组可能的变化,并且能够实现对扩展开放。其包含三种含义:其一,使用接口或抽象类进行边界限定,不允许出现接口或抽象类中不存在的
public方法;其二,参数类型,引用对象尽量使用接口或抽象类;其三,接口的稳定性,接口一旦暴露出去就不能修改,所以对需要暴露的接口持谨慎态度。尽量使用元数据来控制程序的行为,减少重复开发。什么元数据呢?简单点说就是配置参数,参数可以从文件中获得,也可以从数据库中获得。
也就是在一个团队中建立开发章程,并要求所有人员去遵守约定。
对变化的封装有两重含义:第一,将相同的变化封装到一个接口或者抽象类中;第二,将不同的变化封装到不同的接口或抽象类中,不应该有两个不同的变化出现在同一个接口或抽象类中。
好了,到这里面向对象的六大原则就讲完了。