
1.前提
随着开发进度的放慢,程序的主体功能已大致完成,在需求渐渐少下来的时候,我们就需要有计划的对原有的一些代码进行整理,使其结构清晰,更容易被人所阅读,也更容易来进行修改,添加新功能。当然,我个人是不赞成特意分配一些时间来进行重构,也就是把重构当作一个单独的事情区分出来进行特别的处理。我认为当我们在新功能的添加过程中就应该嗅出代码里的坏味道,然后,对代码进行小规模重构,使其能够很顺利的添加新的功能,同时不引入新的问题。但由于历史原因,前期开发也许没有足够的时间,没有详细的设计,以及没有严格的规范要求等等,都使得我们需要在后面的时候里对前期的代码进行重构。目前我的处境正是如此。
2.为什么要进行重构?
我们的整个开发流程首先是要先对程序进行总体的设计,此时的设计是一种根据经验的推测性设计,让程序系统按照既定的想法进行程序的开发;而事情住住不会按照我们预想的那样顺利的进行,或者说不能完全按照我们先前的设计顺利的进行。此时,就需要我们运用重构来修正我们设计上的偏差,让其更加适应需求的变化,保证程序的质量。
这里借用《改善既有代码》一书里的说明。
1.难以阅读的程序,难以修改
2.逻辑重复的程序,难以修改
3.添加新行为时需要修改已有代码时,难以修改
4.带复杂条件逻辑的程序,难以修改
以上四点基本上阐述了需要进行重构的原因,重构就是要解决以上问题,让程序变得容易修改。重构要达到的目的是:
1.容易阅读
2.所有逻辑都只在唯一的地点指定
3.新的改动不会危及现有行为
4.尽可能简单表达条件逻辑
好吧,让我们开始重构吧!
3.重构的难点
4.重构的原则
5.哪些场景需要用到重构
1.Duplicated Code(重复代码)
2.Long Method(过长函数)
3.Large Class(过大的类)
6.常用的重构方法
6.1 提取子函数
提取子函数说的是将一个大的函数通过单一职责原则,将其分为多个功能单一的子函数,提取子函数又需要我们给每个函数取名,良好的函数命令可以起到文档的作用,通过函数名就能大概了解到该函数是做什么的,这样子做会使代码更加清晰,便于阅读和维护。
那么一个函数多长才需要提取子函数呢?其实提取子函数与函数的长度没有太直接的关系,主要是看其完成的具体功能。如果功能不够单一,这个时候就需要提取相应的功能以子函数的形式进行调用了。但有一个不成文的规则吧,就是如果一个函数中的代码超过20行,这个函数就很有可能不只做了一件事情,这是根据个人经验而定的。如果你的代码需要在代码体内使用注释来说明其作用的话,这可能就是一个需要提取子函数的信号了,因为一个函数只完成一个功能嘛。
提取子函数的方法对于编译工具来说,是非常简单的事情,只需要使用快捷键,然后给子函数取一个名字就可以完成提取子函数的重构。这里我们以打印数据库所有学生信息来说明一下,提取子函数的方法。这个函数先要从数据库获取学生信息,然后,对学生信息进行升序排序,最后将学生信息打印。
public void printStuduntsInfo() {
List<StudentInfo> mStudents = new ArrayList<>();
//模拟从数据库读取学生信息
for (int x = 0; x < 50; x++) {
mStudents.add(new StudentInfo(new Random().nextInt(200), "User-" + x));
}
//给学生信息按升序排序
Collections.sort(mStudents, new Comparator<StudentInfo>() {
@Override
public int compare(StudentInfo lhs, StudentInfo rhs) {
return lhs.getId() - rhs.getId();
}
});
//打印学生信息
for (StudentInfo studentInfo : mStudents) {
System.out.println("学号:" + studentInfo.getId() + ",学生姓名:" + studentInfo.getName());
}
}
从上面的函数我们可能看出,该函数做的事情比较多,职责不单一,而且每一部分的功能都有通过注释来说明其作用,我们上面说过,如果在一个函数里需要其使用注释来说明其功能,这时可能是一个函数里做了多件事情了。那我们来对上面的函数使用提取子函数来对其进行重构。
public void printStuduntsInfo() {
List<StudentInfo> mStudents = new ArrayList<>();
getStudentInfoFromDB(mStudents);
StudentInfoSort(mStudents);
printStudentInfo(mStudents);
}
上面是提取子函数后的函数的代码块,非常的清晰;我们通过相应的函数名就能知道其所做的事情,便于阅读;如果我们需要对哪一部分的功能进行修改,只需要找到相应的子函数完成修改即可,不会影响到其它代码,大大降低的修改的成本。
6.2 上移函数到父类
Java面向对象的三大基本特征之一的继承,通过是我们进行代码复用,设计代码的重要手段。而继承如果处理不当也是容易产生重复代码的地方,特别是在对项目类族不是特别熟悉的时候。比如子类A实现了一个方法,而这个方法其实父类里面已经有了实现;或者子类B需要实现某个功能,而子类A里已经有其实现了等等都会造成代码重复,而代码重复的后果就是当逻辑发生变化,而只改了一个地方,另外的地方没有修改,而造成bug。
上移函数的使用场景就是多个子类如果实现了相同的功能,那么就需要考虑将其上移到父类中,让所有子类共用同一个函数,减少代码的重复率、出错率。
上移函数的操作一般是比较简单的,我们需要在父类创建一个函数,然后将子类的功能复制到父类,然后,让子类调用父类的方法。如果每个子类的实现有些许差别,我们可以通过简单修改函数的参数列表以及实现,如果有差异较大的子类,可以让其覆写方法,来完成自己的实现。
public abstract class Vehicle {
public void start() {
System.out.println("启动");
}
public void stop() {
System.out.println("停止");
}
public void speedUp() {
System.out.println("加速");
}
public void speedDown() {
System.out.println("减速");
}
public void openDoor() {
System.out.println("开车门");
}
public void closeDoor() {
System.out.println("关车门");
}
}
我们新建一个奥迪车的具体实现类,该类继承自Vehicle类,但是,在Vehicle并没有转弯的功能,车怎么能没有转弯功能呢,所以,我们在Audi类中添加了相应的功能。
public class Audi extends Vehicle {
public void turn() {
System.out.println("转弯");
}
}
随着业务的发展,我们需要住车的类族中添加宝马车类,我们在使用宝马车类继承Vehicle抽象类。在BMW里添加了转转弯的功能,代码如下:
public class BMW extends Vehicle {
public void turn() {
System.out.println("转弯");
}
}
这里我们可以看出BMW和Audi的实现是一样的,都实现了转弯的功能。当你一段重复的代码写上两遍的时候,我们就应该警觉了,是否将其放到父类中?我们通过上移函数至父类的重构手法,将turn()方法移到父类中,让其子类调用同一个方法。合并后的代码为:
public abstract class Vehicle {
public void turn() {
System.out.println("转弯");
}
}
public class Audi extends Vehicle {
//其它功能函数
}
public class BMW extends Vehicle {
//其它功能函数
}
很多时候上移函数的操作可能不是那么容易发现,这需要对代码的类级结构清晰;同时,多个人开发功能相似的功能时,也容易产生代码重复的情况,导致重复代码越来越多,当然也不是所有的公用函数都需要上移至父类中,有时候我们需要在父类与子类中增加一个中间类,来满足少部分子类的特有需求。因为继承是一种侵略性质代码设计方式,如果选择了继承,就不管你是否需要父类中的某些方法,而一律给予子类。如果某一个子类继承的一个父类,并得到了许多用来到的方法,这时,我们需要考虑这些方法是否需要放在父类,或者我们需不需要继承这个父类。如果说它们的关系可以用什么是什么这样子的关系来表述的,我们就需要考虑将父类中的一些不是那么通用的方法,通过再创建一个中间抽象类,将这些不那么通用的方法移到中间类中,让需要的类去继承这个中间类,而不需要的,直接继承父类。这种实现方法就是我们接下来要说的下移函数到子类。
6.3 下移函数到子类
在面向对象的类族体系结构当中,除了同一段代码在多个子类中都有重复的实现外,还有一种情况,是父类中有子类不需要的函数,导致子类被强行拥有了自己并不需要的函数,这也是一种耦合。这种情况恰恰与我们上移函数至父类相反,我们需要将不是所有子类共用的方法移到父类的下一个类型层次,让其继承父类,然后让那些需要使用这些不是通用功能的子类来继承它。
我们还是以上面的vehicle为例,上面的例子中在父类有一个开门、关门的两个操作,而由于业务需要,我们添加了自行车类,而自行车类是没有开门、关门的操作的。这时我们需要使用下移函数至子类的重构手法,将开门和关门的操作定义到中间类中,让需要的子类去继承。具体操作为:
1.定义中间类
我们定义一个中间类Car,将开门、关门的动作移至该类,然后让该类继承至Vehicle类,专门让汽车类去继承它。
public abstract class Car extends Vehicle {
public void openDoor() {
System.out.println("开车门");
}
public void closeDoor() {
System.out.println("关车门");
}
}
2.让具体汽车类继承Car类
public class Audi extends Car {
//其它功能函数
}
3.让不是汽车类继承Vehicle类
public class bike extends Vehicle {
//其它功能函数
}
通过下移函数至子类,将并不是通用的功能移到了合适的层次,让相应的子类去选择合适的父类继承。配合上移函数到父类的重构手法,可以减少大量的重复代码和避免父类与子类过度的耦合关系。
6.4 封装固定的业务逻辑
这里主要说的是当我们有一个固定的业务逻辑需要被多次调用时,避免代码重复和可维护性,我们需要使用封装将业务逻辑整理到一起,固定执行。比如,上面Car的例子,我们模拟智能汽车来实现加速的效果。我们需要打开车门,启动汽车,加速这三个步骤。比如,我们分别使用BMW和Audi来实现加速效果:
BMW bmw = new BMW();
bmw.openDoor();
bmw.start();
bmw.speedUp();
Audi audi=new Audi();
audi.openDoor();
audi.start();
audi.speedUp();
上面我们分别实现了两台车的加速过程,但是我们能很明显的发现,它们的调用逻辑,调用顺序是完全相同的,除了具体的类不同之外。这样子就导致了代码的重复,如果有多台车,那么我们需要写多次同样的代码,这将是一个灾难。此时我们就应该使用封装固定的业务逻辑的重构手法来对重复代码进行重构。
我们需要再定义一个智能汽车的类,继承自Car类,然后提供加速的业务逻辑封装后的方法autoSpeedUp().具体代码如下:
public abstract class SmartCar extends Car {
public void autoSpeedUp(int speed) {
this.openDoor();
this.start();
this.speedUp();
System.out.println("当前加速为" + speed);
}
}
如果是智能汽车类的话,我们直接继承至SmartCar类,如果我们需要更改父类中的实现方式,我们子类可以通过覆写父类的相应方法来完成自己的不同实现。这里的autoSpeedUp()方法实际上是用到了模板方法的设计模式来对固定的业务逻辑进行封装。通过这种封装我们可以提高代码的维护性,减少代码的重复率。
6.5使用泛型去除重复的逻辑
当我们不了解泛型时,如果要对多种数据类型作相同的逻辑的操作,这时我们会创建很多重复的代码只是操作的数据类型不一样而已,这样子对我们编程人员来说,简直就是灾难。每使用一个新的数据类型,都是复制一份同样的代码,改一下操作的类型,这样子存在很大的问题,如果一处逻辑需要改动,那么就需要多个地方一起改动,而这种改动又很容易漏改,直到运行时才发现问题。
如果我们碰到这样子的代码,那么我们就需要考虑使用泛型来减少重复代码,复用逻辑了。我们使用一个例子分别实现不带泛型和使用泛型的实现来对比使用泛型的代码减少、逻辑复用。首先我们分别使用Int和String来实现一个简单的List的操作,分别实现get()、add()、size()三个方法。
IntArrayList的实现
public class IntArrayList {
private int[] dataList;
public IntArrayList(int size) {
dataList = new int[size];
}
public int get(int pos) {
if (dataList.length > pos) {
return dataList[pos];
}
return -1;
}
public void add(int pos, int data) {
dataList[pos] = data;
}
public int size() {
return dataList.length;
}
}
public class StringArrayList {
private String[] dataList;
public StringArrayList(int size) {
dataList = new String[size];
}
public String get(int pos) {
if (dataList.length > pos) {
return dataList[pos];
}
return "";
}
public void add(int pos, String data) {
dataList[pos] = data;
}
public int size() {
return dataList.length;
}
}
上面的两种实现可以看出,除了操作的类型不一样,逻辑是完全一样的,这时我们通过使用泛型来改变一下实现方式。
使用泛型实现
public class SimpleArrayList<T> {
private T[] dataList;
public SimpleArrayList(int size) {
dataList = (T[]) new Object[size];
}
public T get(int pos) {
return dataList[pos];
}
public void add(int pos, T data) {
dataList[pos] = data;
}
public int size() {
return dataList.length;
}
}
使用泛型,我们将具体的数据类型使用T来代替,当运行时会被赋值为具体的类型;在创建数组时,我们并不知道创建什么类型的数组,而又不能直接new T[]来创建,因为创建的对象必须都是具体的对象。而所有的类型都是继承自Object,所以这里使用new Object[]来创建数组,然后再强转成T[]类型。最后在add时,我们添加的是T类型的数据,具体由用户来指定。这样一来我们就不需要再重复创建相应逻辑的代码,达到复用代码的目的,一份代码大大降低的修改的复杂度。
我们再来看看相应的使用吧,我们分别使用上面三种方法来实现数据的添加和获取。
//使用InArrayList类
IntArrayList intArrayList=new IntArrayList(5);
intArrayList.add(0,2);
intArrayList.add(1,25);
System.out.println(intArrayList.get(1));
//使用StringArrayList类
StringArrayList stringArrayList=new StringArrayList(5);
stringArrayList.add(0,"hello");
stringArrayList.add(1,"world");
System.out.println(stringArrayList.get(0));
//使用SimpleArrayList来实现上面两种类型的操作
SimpleArrayList<Integer> intArrayList1=new SimpleArrayList<>(5);
intArrayList.add(0,2);
intArrayList.add(1,25);
System.out.println(intArrayList1.get(1));
SimpleArrayList<String> stringArrayList1=new SimpleArrayList<>(5);
stringArrayList1.add(0,"hello");
stringArrayList1.add(1,"world");
System.out.println(stringArrayList1.get(0));
6.6 使用对象避免过多的参数
当我们的项目变得复杂,会出现越来越多的函数需要带有多个参数的情况,你总能看到特定的一组参数总是一起被传递,可能有好几个函数使用了这组特定的参数,它们可能都在一个类里,也有可能各有其主。如果出现这种情况,我们就需要使用一个对象来对这些参数进行一层封装,然后通过传递此对象而不是一组参数来完成数据的传递。比如,最常见的就是第三方分享操作了。
例如,我们需要创建一个分享到微信朋友圈的功能,我们需要传递标题,内容,图片,原文链接和原文作者这五个参数。
/**
* 分享到微信朋友圈
* @param title 标题
* @param content 内容
* @param imgUrl 图片url
* @param targetUrl 原文链接
* @param creator 原文作者
*/
public void shareToWXFriend(String title,String content,String imgUrl,String targetUrl,String creator) {
//完成分享到朋友圈的逻辑
}
上面我们使用了五个参数,下面我们来调用这个方法:
shareToWXFriend("重构手法","常用的重构手法介绍和使用","http://url.com","http://targetUrl.com","xxxx");
当我们看到这一连串的参数时,你可能也不太清楚哪个参数具体代表什么意思了,而且当你不需要传递某个参数时,你还需要手动的将其设置为null。我们可以将上面的五个参数封装到一个对象里:
/**
* 分享信息类
*/
public class ShareInfo {
public String title;
public String content;
public String imgUrl;
public String targetUrl;
public String creator;
}
我们通过ShareInfo对象来替换上面的五个参数:
public void shareToWXFriend(ShareInfo shareInfo) {
//完成分享到朋友圈的逻辑
}
此时我们就可以通过传递对象的方式来代替传递一大堆不是很清楚什么意思的参数来简化调用逻辑了,当我们在创建对象时,我们可以通过其字段名来获得当前参数的意思,而且不需要被传递的数据,也不再需要手动设置为null了,最重要的是整个方法看起来更加简洁,便于理解和维护。
6.7 转移函数
有时候我们的类中包含了太多的函数,或者一个类与另一个类有太多的函数调用,导致类之间的过度耦合。此时,我们需要考虑是否需要对函数来做一次整理,让合适的函数放到合适的类中,松散耦合。
然而转移函数的难易程度跟项目的复杂程度有关,如果在一个比较复杂的项目中进行转移函数,其实是并没有那么容易的。我们要转移一个函数,而这个函数里调用了其它函数,有可能其它函数又调用了相应的函数或者字段。对于这种内部耦合性较强的函数,我们在转移时,要么将内部类中先将函数解耦,解决一些不需要的函数之间的调用,如果是必须的调用关系,我们就需要考虑是否要将多个函数和字段整体转移,有时候转移整个函数链比只转移一个函数要简单得多,当然前提是这些函数链都应该被转移到另一个类型中去。
将一个函数转移到另一个新的类型中,一般要对函数根据新的类型进行重新命名,因为在新的类型中,同样的函数可能有不同的解释。同时,在移到的过程中,我们可以保留原函数,通过代理的方式,让其兼容老的调用;如果没有相应的调用就可以直接删除原函数。
接下来我们以一个简单的例子来说明,转移函数的一些应用吧。我们以班级和学生为例,班级类有一个添加学生的方法,然后学生类就是一个存储学生信息的类,里面包含了一个是否是某个班级的判断。
//学生类
public class Student {
private String name;
private int id;
public Student(String name, int id) {
this.name = name;
this.id = id;
}
}
/**
* 是否是当前班级的判断
* @param aClass
* @return
*/
public boolean isBelongTo(AClass aClass) {
for (Student student : aClass.getClassStudent()) {
if (student.id == this.id) {
return true;
}
}
return false;
}
//班级类
public class AClass {
private List<Student> mStudents = new ArrayList<>();
public void add(Student student) {
mStudents.add(student);
}
public List<Student> getClassStudent() {
return mStudents;
}
}
这里我们在学生类里面创建了一个当前学生是否属于某个班级判断,这个方法主体是操作班级类里的信息,而只是调用了student的一个字段,所以我们需要把合适的函数移到合适的类中。
public class AClass {
private List<Student> mStudents = new ArrayList<>();
public void add(Student student) {
mStudents.add(student);
isContain(student);
}
public List<Student> getClassStudent() {
return mStudents;
}
/**
* 是否是当前班级的判断
*
* @param student
* @return
*/
public boolean isContain(Student student) {
for (Student stu : getClassStudent()) {
if (stu.getId() == student.getId()) {
return true;
}
}
return false;
}
}
我们在AClass类里添加了一个isContain()的方法,来判断当前班级是否包含该学生。然后将Student类中的isBelongTo()方法设置为代理函数,在内部调用班级类的isContain()方法。然后将学生类中的isBelongTo()方法通过@Deprecated声明其已过时,尽量让其它类不要调用此函数。
//学生类
public class Student {
private String name;
private int id;
public Student(String name, int id) {
this.name = name;
this.id = id;
}
/**
* 是否是当前班级的判断
*
* @param aClass
* @return
*/
@Deprecated
public boolean isBelongTo(AClass aClass) {
return aClass.isContain(this);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
到这里,这个班级里是否包含某个函数已经转移完毕。我们来实际调用一下这两个类。
Student stu1 = new Student("zhangshan", 1);
Student stu2 = new Student("lisi", 2);
Student stu3 = new Student("wangwu", 3);
AClass aClass = new AClass();
aClass.add(stu1);
aClass.add(stu2);
aClass.add(stu3);
System.out.println("学生:" + stu1 + "是否属于该班级:" + aClass.isContain(stu1));
System.out.println("学生:" + stu3 + "是否属于该班级:" + aClass.isContain(stu2));
System.out.println("学生:" + stu2 + "是否属于该班级:" + aClass.isContain(stu3));
通过转移函数的重构手法,可以让类与类之间松散耦合,简化类之间的关系,易于理解。但通常在实际项目中来进行函数转移时,并不是一件容易的事情,我们需要做好版本控制,当我们在转移函数过程中,如果被丝一般的耦合所困扰,没有思路的时候,我们可以回滚代码,整理思路,重新出发。
6.8 将状态码转换为状态模式
当你需要根据某种状态来执行不同行为的时候,这时,你可以考虑使用状态设计模式来进行设计或者重构。一般来说,像多个if-else或者switch可能就是我们需要寻找的目标并做出相应改变的地方。
比较典型的手法就是将if-else通过转换成多态来解决问题的手法。如果我们使用条件式时,当新增加一种类型,我们需要查找并更新所有条件式。而如果使用多态,我们只需要增加一个新类型的子类,在子类里包装相应的行为,然后在合适的时机注入到该对象即可。用户不需要了解子类的实现情况,只需要在特定的状态下进行相应的调用就可以了,这样做,减少了系统间的相互依赖程序,同时,使系统变得更加的简单,易于理解,使升级变得容易。
例如,我们还是拿汽车的例子来说明该重构手法。汽车有停止、启动、加速这三种状态,它具备下面这些规则:
- 停止时才可以启动
- 启动时才可以停止、加速
- 加速时可以停止
而在车子停止时不能加速,车子在启动时不能再次启动,车子在加速时也不能启动。总之,在对应的状态下只能做该状态下能做的事情。示例代码如下:
public abstract class Vehicle {
public final int STOP_STATUS = 0; //停止状态
public final int START_STATUS = 1; //启动状态
public final int DRIVING_STATUS = 2; //加速状态
private int currentStatus = STOP_STATUS; //初始状态
public void setStatus(int status) {
this.currentStatus = status;
}
public void start() {
if (currentStatus == START_STATUS) {
System.out.println("启动");
}
}
public void stop() {
switch (currentStatus) {
case START_STATUS:
case DRIVING_STATUS:
System.out.println("停止");
break;
}
}
public void speedUp() {
if (currentStatus != STOP_STATUS) {
System.out.println("加速");
}
}
}
上面的代码我们定义了一个vehicle类,然后分别在start()、speedup()、stop()这三个函数中进行了相应的判断,为了满足相应状态执行相应的行为,我们在相应函数里做了大量充斥着if-else、switch的操作。让代码变得非常复杂,如果需要新增加一个状态,那么需要在每一种状态里修改相应的判断逻辑,随着状态的增多,这将是一个灾难,难以维护。但这里我们是根据某种状态来完成相应的行为,也很容易让人联想到状态模式,状态模式能够很好地将这类根据条件判断来修改行为的丑陋代码消除。我们来通过状态模式来对代码进行修改。
我们先来看看创建的状态类:
public abstract class VehicleState {
public boolean start() {
return false;
}
public boolean stop() {
return false;
}
public boolean speedup() {
return false;
}
}
我们将所有会根据状态执行的行为函数都写到了状态类中,这是让其子类选择去覆写符合自己状态行为的具体实现。我们再来看看具体状态行为的实现。
public class DrivingState extends VehicleState {
@Override
public boolean speedup() {
System.out.println("加速");
return true;
}
@Override
public boolean stop() {
System.out.println("停止");
return true;
}
}
public class StopState extends VehicleState {
@Override
public boolean stop() {
System.out.println("停止");
return true;
}
}
public class StartState extends VehicleState {
@Override
public boolean start() {
System.out.println("启动");
return true;
}
@Override
public boolean speedup() {
System.out.println("加速");
return true;
}
}
有了相应的状态的实现后,我们需要在Vehicle类中应用该状态类。vehicle的代码修改如下:
public abstract class Vehicle {
private VehicleState currentStatus; //当前状态
public void setStatus(VehicleState status) {
this.currentStatus = status;
}
public void start() {
if (currentStatus.start()) {
//这里说明 如果当前开启状态确实被执行了,而不是调用了父类的空方法,此时才会更改状态
currentStatus = new StartState();
}
}
public void stop() {
if (currentStatus.stop()) {
currentStatus = new StopState();
}
}
public void speedUp() {
if (currentStatus.speedup()) {
currentStatus = new DrivingState();
}
}
}
这里我们在相应的方法中都做了一个判断,主要是为了解决这样子的一个问题,比如说,我们此时传入的状态是stopState,而此时我们调用了speedUp()函数,因为stopState中是没有此函数的,于是,执行了父类的空函数,然后将状态改成了DrivingState,而这里其实真正的stop函数根本没有执行,所以是不应该改变其状态为DrivingState的。所以,这里的判断就是为了规避这样子的一种情况的发生。
这样子通过将条件式改成了多态来实现,大大减轻了新增状态的工作量,结构清晰,便于扩展,这是非常理想的一种状态。所以,如果大家在重构时看到因为状态的改变而需要修改相应的执行行为时,果断改用状态模式吧。
6.9 什么也不做的对象——nullObject模式
在开发过程中,我们经常会调用某个对象的某个方法,在调用时,先对其对象进行是否为空的判断,如果需要多次调用,就需要进行多次的判空操作,如果一不小心让了判断,可以会引发NullPointException异常。为了避免这种情况,我们可以使用NullObject模式来规避这种情况的发生。
我们现在用一个简单的新闻客户端的例子来说明一下。这个新闻客户端里有一个统计分析的模块,在多处地方我们都需要调用这个分析模块来记录一些数据,也就是获得对象,调用其方法来发送一些消息。
public interface StatisticsAPI {
void send(String newMessage);
}
//配置类
public class Config {
StatisticsAPI mStatisticAPI;
public void setmStatisticAPI(StatisticsAPI api) {
this.mStatisticAPI = api;
}
public StatisticsAPI getStatisticAPI() {
return mStatisticAPI;
}
}
这时有一个问题,就是我们在调用getStatisticAPI()来获取StatisticsAPI时,这个对象不一定已经被注入,也就是有可能获取值为null。我们来看看客户端调用分析模块的代码:
public class NewsApp {
Config mConfig;
public NewsApp(Config config) {
this.mConfig = config;
}
public void userClick() {
if (mConfig.getStatisticAPI() != null) {
mConfig.getStatisticAPI().send("user click");
}
}
public void userReadNews() {
if (mConfig.getStatisticAPI() != null) {
mConfig.getStatisticAPI().send("user read news");
}
}
}
在客户端我们通过构造函数注入Config配置类,然后,通过配置类去调用统计模块的API,而这里获取统计数据对象的方法有可能会为空,所以,我们每次都对其进行了是否为空的判断。当我们调用的次数越多,判断为空的工作量也随之增加,这并不是我们想看到的,下面我们使用NullObject模式来对上面代码改造一下。
//空对象
public class NullStatisticsAPI implements StatisticsAPI {
@Override
public void send(String newMessage) {
System.out.println("什么也没有做,只是避免判空而已");
}
}
//配置类
public class Config {
StatisticsAPI mStatisticAPI;
//不会被改变的null对象
public static final NullStatisticsAPI nullStatisticsAPI = new NullStatisticsAPI();
public void setmStatisticAPI(StatisticsAPI api) {
this.mStatisticAPI = api;
}
public StatisticsAPI getStatisticAPI() {
return mStatisticAPI == null ? nullStatisticsAPI : mStatisticAPI;
}
}
这里的配置类有两点改变,一是我们在其内创建了一个静态不可变的null对象,然后,在getStatisticAPI()方法中,如果其为空就返回NullStatisticAPI空对象来防止其返回空的情况。有效防止为空所引发的一些问题。接下来我们再看看改造后的新闻客户端的调用情况。
public class NewsApp {
Config mConfig;
public NewsApp(Config config) {
this.mConfig = config;
}
public void userClick() {
mConfig.getStatisticAPI().send("user click");
}
public void userReadNews() {
mConfig.getStatisticAPI().send("user read news");
}
}
这里我们直接去掉了统计对象为空的判断。这样一来我们就减少了很多判空的操作,我们来测试一下我们的NullObject的作用吧。
Config config = new Config();
config.setmStatisticAPI(new TestStatisticAPI());
NewsApp newsApp = new NewsApp(config);
newsApp.userClick();
newsApp.userReadNews();
config.setmStatisticAPI(null);
newsApp.userClick();
newsApp.userReadNews();
其打印的结果如下:
user click
user read news
什么也没有做,只是避免判空而已
什么也没有做,只是避免判空而已
从打印结果中我们可以看到,NullObject已经生效了,我们已经成功的规避了为null的情况。为了安全起见,NullObject一定是常量,因为它们任何时候都不需要进行变化,也没有必要进行变化。
6.10 让类保持苗条身材——分解胖类型
我们最开始说了个提取子函数,根据单一职责原则来对large Method进行了”瘦身”,而这里说的让胖类型减肥,保持”苗条身材”,两者如出一辙,只是范围变大了而已。这里主要说的是让类也满足单一职责原则。
在开始写某一个类时,如果我们没有对其进行规划,进行拆分的话,大多数情况下,我们都会把巨多的函数写在同一个类里,而且随着需求的增加,我们会往其内写入更多的函数。让其变得越来越臃肿,越来越难以维护。所以在编写新类时,我们要先进行分析,将其按照功能的类别来进行划分,并组织到不同的类中来进行组合实现相应功能。这样做的好处是各个类职责单一,结构相对简单,便于扩展和维护。
当我们最开始在使用ImageLoader来完成简单的图片显示时,我们经常会碰到下面的代码,大致的代码是这样的:
public class ImageLoader {
private Map<String, Bitmap> mMemCache = new LinkedHashMap<>();//内存缓存
private Map<String, Bitmap> mDiskCache = new LinkedHashMap<>(); //硬盘缓存
public void displayImage(ImageView imageView, String url) {
Bitmap bitmap = decodeFromCache(url);
if (bitmap == null) {
bitmap = decodeFromDisk(url);
}
if (bitmap == null) {
bitmap = downloadImageFromNet(url);
}
imageView.setImageBitmap(bitmap);
cache(url, bitmap);
}
/**
* 缓存图片
*/
private void cache(String url, Bitmap bitmap) {
cacheInMem(url, bitmap);
cacheInDisk(url, bitmap);
}
private void cacheInDisk(String url, Bitmap bitmap) {
mDiskCache.put(url, bitmap);
}
private void cacheInMem(String url, Bitmap bitmap) {
mMemCache.put(url, bitmap);
}
/**
* 从网络获取图片
*/
private Bitmap downloadImageFromNet(String url) {
System.out.println("从网络获取图片");
return BitmapFactory.decodeFile(url);
}
/**
* 从硬盘获取图片
*/
private Bitmap decodeFromDisk(String url) {
System.out.println("从硬盘获取图片");
return mDiskCache.get(url);
}
/**
* 从内存获取图片
*/
private Bitmap decodeFromCache(String url) {
System.out.println("从内存获取图片");
return mMemCache.get(url);
}
}
在上面简单的ImageLoader的实现中,我们将图片的加载逻辑,图片的下载逻辑,图片的缓存逻辑都写在了同一个类里,很显然,这个类的职责太多了。而且下载图片、缓存图片这些功能都是会变的,因为我们可能会将下载引擎换成okhttp、将图片使用LRU。当需求出现变更我们需要在这个复杂的逻辑中去修改,维护成本非常高。
所以我们需要对这个类进行按照图片下载、图片缓存、图片显示这三部分来对上面的代码进行重构,使其满足单一职责原则。
//图片下载类
public class ImageDownload {
/**
* 从网络获取图片
*/
public Bitmap downloadImageFromNet(String url) {
System.out.println("从网络获取图片");
return BitmapFactory.decodeFile(url);
}
}
//图片缓存类
public class ImageCache {
private Map<String, Bitmap> mMemCache = new LinkedHashMap<>();//内存缓存
private Map<String, Bitmap> mDiskCache = new LinkedHashMap<>(); //硬盘缓存
/**
* 缓存图片
*/
public void cache(String url, Bitmap bitmap) {
cacheInMem(url, bitmap);
cacheInDisk(url, bitmap);
}
private void cacheInDisk(String url, Bitmap bitmap) {
mDiskCache.put(url, bitmap);
}
private void cacheInMem(String url, Bitmap bitmap) {
mMemCache.put(url, bitmap);
}
/**
* 从硬盘获取图片
*/
private Bitmap decodeFromDisk(String url) {
System.out.println("从硬盘获取图片");
return mDiskCache.get(url);
}
/**
* 从内存获取图片
*/
private Bitmap decodeFromCache(String url) {
System.out.println("从内存获取图片");
return mMemCache.get(url);
}
/**
* 向外暴露的获取图片的方法
*/
public Bitmap getBitmap(String url) {
Bitmap bitmap = decodeFromCache(url);
if (bitmap == null) {
bitmap = decodeFromCache(url);
}
return bitmap;
}
}
//图片显示控制逻辑
public class ImageLoader {
private ImageCache imageCache = new ImageCache(); //图片缓存类
private ImageDownload imageDownload = new ImageDownload(); //图片下载类
public void displayImage(ImageView imageView, String url) {
Bitmap bitmap = imageCache.getBitmap(url);
if (bitmap == null) {
bitmap = imageDownload.downloadImageFromNet(url);
}
imageView.setImageBitmap(bitmap);
imageCache.cache(url, bitmap);
}
}
到这里我们就完成了对上面简单的ImageLoader进行了功能的拆分,将原来一个类分为了三个类来进行组合,解决了单一类职责过多,难以维护的问题。这样做之后,各个类的代码相对较少,逻辑单一,代码简单,结构清晰,易于维护。
6.11 重新组织函数
InLine Method(内联函数)
这里所说的与我们的提取子函数恰好相反,主要解决的是这样子的两种情况:一个函数的本体与其函数名称同样清晰易懂,在函数调用点插入函数本体,然后移除该函数;或者是提取子函数的动作不是很合理,将其全部子函数进行恢复到函数本体后,再对其进行提取子函数的操作。
一个函数本体与其函数名称同样清晰的例子:
public int getRating(int num) {
return isMoreFive(6) ? 2 : 1;
}
public boolean isMoreFive(int num) {
return num > 5 ? true : false;
}
isMoreFive()方法表示当前数是否大于5,而函数体内的表达式也可以非常明确的表示此含义,所以我们可以将上面的代码进行重构。代码如下:
public int getRating(int num) {
return num > 5 ? 2 : 1;
}
这样子做之后,代码更加简洁,而所要表达的意思却没有发生变化。我们非常看好这样子做减法的操作。
关于函数提取不合理,需要使用内联函数的方式,将其所有代码先放回原函数再来重新提取的手法,我这里就不用例子了,但是需要简单的说明一下,就是当函数的提取没有满足单一职责或者很多的函数看上去只是在做其它函数的委托,而没有太大存在意义的时候,我们可以使用此方法来进行重构。
Inline Temp (内联临时变量)
你有一个临时变量,它只被一个简单的表达式赋值过一次,但这个临时变量妨碍了其它的重构手法。这时我们可以将这个临时变量移除,然后用给临时变量赋值的表达式来对临时变量进行替换。
double currentPrice = originPrice * 0.98;
return currentPrice > 1000;
将其替换为:
return originPrice * 0.98 > 1000;
Replace Temp with Query(用查询取代临时变量)
你的程序以一个临时变量来存储一个表达式的运算结果,将这个表达式提炼到一个函数中去,然后,将所有使用这个临时变量的地方都替换成新的函数。这样做的目的是为了让新的函数可以被其它地方所使用。
double basePrice = quantity * price;
if (basePrice > 500) {
return basePrice * 0.95;
} else {
return basePrice * 0.98;
}
这里我们使用了一个临时变量basePrice来存储了计算价格的表达式。这时,我们可以将这个表达式提炼到一个函数中,然后再通过函数来引用这个表达式。
public double getPrice(int quantity, double price) {
if (getBasePrice(quantity, price) > 500) {
return getBasePrice(quantity, price) * 0.95;
} else {
return getBasePrice(quantity, price) * 0.98;
}
}
private double getBasePrice(int quantity, double price) {
return quantity * price;
}
这个重构手法我觉得需要考虑此抽离的表达式是否其它地方还需要被引用,也就是要考虑一下利弊,因为我觉得这里每次都去调用一次相应的函数,然后进行计算的话,总是没有一次就把值存储起来而每次直接取值来的划算,除非此函数真的被其它地方引用到。
Introduce Explaining Variablexhty(引入解释性变量)
你有一个复杂的表达式,可以将这个表达式或者表达式的一部分赋值给临时变量,以此临时变量的名称来解释其所表达的意义。
if (platform.toUpperCase().indexOf("ANDROID")>-1
&& brower.toUpperCase().indexOf("UC")
&&isInstalled()&&resize>0) {
//do someString
}
这里我们在条件里写了很多的表达式来作判断,造成我们的条件不容易被理解,这种情况下,我们需要引入解释性变量,让每个条件表达式的意思变得理清晰,便于理解。
boolean isAndroidPlatform = platform.toUpperCase().indexOf("ANDROID") > -1;
boolean isUCBrower = brower.toUpperCase().indexOf("UC");
boolean isNotZero = resize > 0;
if (isAndroidPlatform
&& isUCBrower
&& isInstalled() && isNotZero) {
//do someString
}
Split Temporary Variable(分解临时变量)
你的程序中某个临时变量被赋值不只一次,而这个临时变量所记录的信息既不是循环变量,也不是收集计算结果,针对每次赋值建立一个独立、对应的临时变量。 这里主要说的是,每个临时变量都有自己的职责,虽然可以使用同一个临时变量完成所有的操作,但是每次临时变量所承担的责任是不相同的。这样子的情况下,我们需要在每次对临时变量进行赋值时,考虑是否此时的赋值的意义是否与上一次的赋值意思相同,如果不同,此时我们需要使用一个新的临时变量来对其值进行存储。
int result = 0;
int velocity = 100;
int carDistance = velocity * 6;
velocity = 10;
int bikeDistance = velocity * 6;
return carDistance + bikeDistance;
上面我们通过velocity来分别记录了汽车的速度和自行车的速度,也就是有两个职责。而我们使用了一个变量来进行存储。虽然结果是一样的,但是在看函数时,可能会给阅读者带来困惑,两个不同意思的值使用了同一个临时变量进行了存储,会让人产生歧义。我们使用分解临时变量的重构手法来对其进行重构:
int result = 0;
int carVelocity = 100;
int carDistance = carVelocity * 6;
int bikeVelocity = 10;
int bikeDistance = bikeVelocity * 6;
return carDistance + bikeDistance;
我们将第一次的赋值所对应的临时变量修改为carVelocity,而将第二次赋值,我们修改为bikeVelocity,这样子将两次不同意义的赋值分别用两个临时变量进行存储,意义明确。
Rmove Assignments to Parameters(移除对变量的赋值)
函数中对其参数进行直接赋值,可以将参数先使用临时变量存储,然后再修改其临时变量的值。在Java中参数的传递使用的是值传递的方式,对于基本数据类型的传递直接修改其参数可能不会有多大的问题,但是如果是对对象进行修改的话,可能得到的结果并不是你所想要的。而且这样子的写法也是不太符合代码规范的操作。
public int getDiscount(int inputValue) {
if (inputValue > 100) {
inputValue -= 2;
}
return inputValue;
}
将其修改为:
public int getDiscount(int inputValue) {
int result = inputValue;
if (result > 100) {
result -= 2;
}
return result;
}
Replace Method with Method Object(使用函数对象取代函数)
你有一个大型函数,其中对局部变量的使用使你很难使用提取子函数的操作,这种情况下,我们可以将这个函数放进一个单独的对象中,如此一来局部变量就变成了对象中的成员变量,而函数所接收的参数通过此对象的构造方法传入。然后你可以在同一个对象将这个大型函数分解为多个小型函数。
这个方法是我之前没有使用过,而又感觉非常棒的一种解决思路。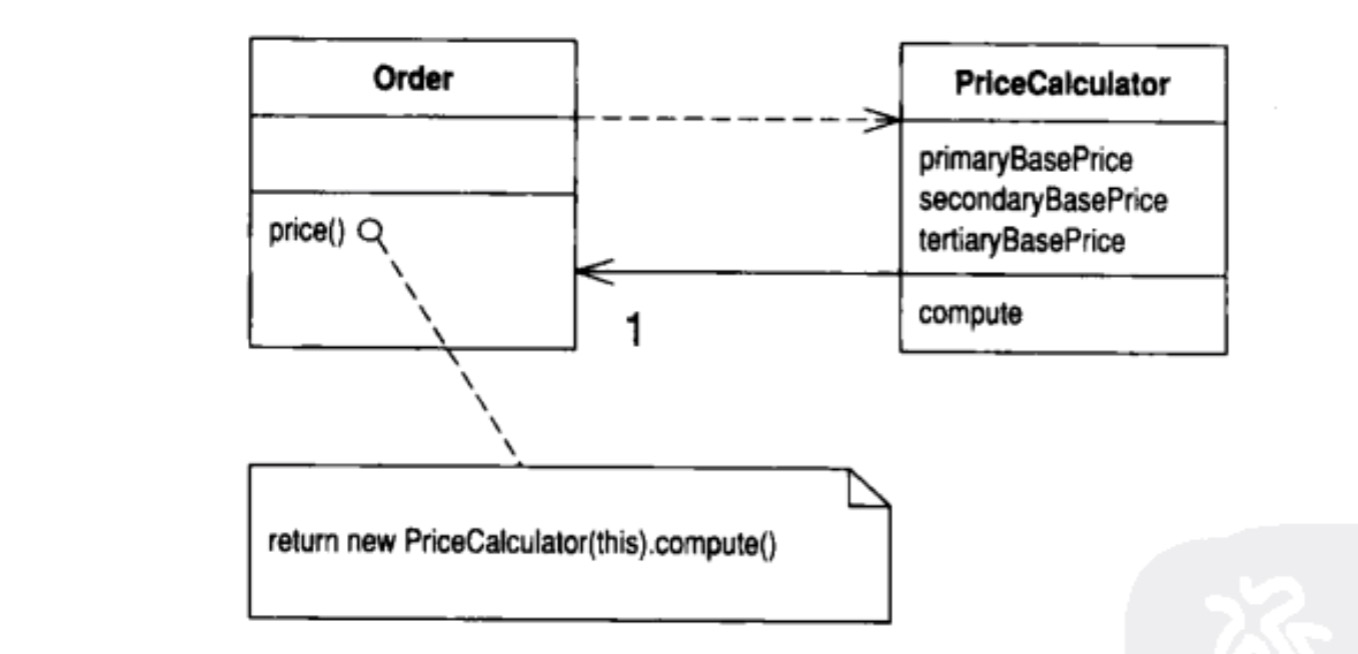 我们通过将
我们通过将price()方法里的大型函数抽离到一个新的对象PriceCalculator中,将其局部变量直接变成新对象里的字段,然后将再对其函数进行了抽取compute()子函数。在原来引用的地方我们通过内部创建新的对象,并调用其compute()函数来完成其功能。
public class Acount {
public double getTotalPrice(int inputVal, int quantity, int dateToYear) {
double price1 = inputVal * 0.7;
double price2 = inputVal * dateToYear + 100;
if (dateToYear > price1) {
price2 -= 20;
}
double price3 = price1 * quantity / 3 + delta();
return price1 + price2 + price3;
}
}
我们将这个getTotalPrice()方法通过函数对象的方式来对其进行替换。首先我们将其参数和局部变量都变成新对象里的字段。
private int inputVal;
private int quantity;
private int dateToYear;
private double price1;
private double price2;
private double price3;
private Acount source;
然后,将参数通过构造函数来进行传递进来。
public PriceCalculator(Acount source, int inputVal, int quantity, int dateToYear) {
this.inputVal = inputVal;
this.quantity = quantity;
this.dateToYear = dateToYear;
this.source = source;
}
这里我们将原函数参数列表中的三个参数都通过构造函数传递了进来,而且将原对象本身也传递了进来,为了对原来函数进行调用。
public double compute() {
price1 = inputVal * 0.7;
price2 = inputVal * dateToYear + 100;
if (dateToYear > price1) {
price2 -= 20;
}
price3 = price1 * quantity / 3 + source.delta();
return price1 + price2 + price3;
}
这里针对原函数进行了抽取子函数的操作,对应compute()函数。在此函数里我们使用了相应了六个字段,还通过原函数的对象调用了原函数里的方法来完成函数的功能。
public double getTotalPrice(int inputVal, int quantity, int dateToYear) {
return new PriceCalculator(this, inputVal, quantity, dateToYear).compute();
}
最后我们修改了原函数以委托的形式来调用了新创建的对象完成了相应了功能转移。
6.12 在对象之间搬移特性
Move Method (搬移函数)
你的程序中,有一个函数与其所属类外的其它类有着更为密切的交流;这时,在该函数最常引用的类中建立一个有着相似功能的新函数,然后将旧函数变成一个委托函数,也就是直接在旧函数里调用新函数;或者直接删除旧函数,并相所有对旧函数的引用改为引用新函数。
这里所说的和我们上面 6.7转移函数说的意思是一样的。所以这里就不再熬述。
Move Filed(搬移字段)
这个和搬移方法类似。你的程序中,某个字段被其所属类之外的其它类更频繁的使用到,在目标类中新建字段,在源字段所属的类中调用新建的字段。在Move Method时,我们一般会先使用Move Filed方法。
多数情况下,我们在移动字段前,如果字段是public访问权限时,我们通常先使用private将其修改后,使用函数来对其进行调用。这样,不管字段移动到何处,我只需要改动其调用函数就可以了,而不需要对每处调用都进行修改。
Extract Class(提炼类)
某个类做了应该使用两个或者更多类所做的事。建立一个或多个新类,将其一部分字段和函数移到相应的类中,让每个类尽量满足单一职责。这里和我们上面6.10让类保持苗条身材——分解”胖类型”的意思是一致的。
Inline Class(将类内联化)
这个刚好与Extract Class相反。某个类没有做太多的事情,将这个类里所有的字段和函数移到另一个类中,然后将此类删除。
如果一个类没有承担太多的责任,不再有单独存在的理由,(通常是由于之前的重构抽取了其责任),这里我们需要将此”萎缩类”合并到与其调用最频繁的类中去,然后删除此“萎缩类”。
具体的操作步骤是:
- 在目标类身上声明源类的所有使用public修辞的函数,并实现其功能,并将源类中的所有public函数变成委托函数,让其调用目标类中新声明的函数,看是否运行正常。
- 将源类中所有
public修辞改为private修辞,让其所有源类的引用点,改而引用目标类。- 再使用
Move Method或者Move Filed手法将其所有字段和函数移至目标类。
这里我们写一个简单的例子来说明一下吧。
public class Person {
private String name;
private Telephone telephone = new Telephone();
public String getName() {
return name;
}
public Telephone getTelephone() {
return telephone;
}
public String getTelephoneNum() {
return telephone.getTelephoneNum();
}
}
public class Telephone {
private String telephoneNum;
private String areaCode;
public void setTelephoneNum(String telephoneNum) {
this.telephoneNum = telephoneNum;
}
public String getAreaCode() {
return areaCode;
}
public void setAreaCode(String areaCode) {
this.areaCode = areaCode;
}
public String getTelephoneNum() {
return telephoneNum;
}
}
这里有两个类,一个Person类,一个Telephone类,Telephone类经过Move Method和Move Filed方法重构之后,只剩下telephoneNum和areaCode两种属性。而这两个属性不足支撑其作为一个单独的类而独立存在。而与其交流最频繁的类是Person类,在此,我们需要把一个不需要存在的类通过内联重构手法将其组合到与其交流最频繁的类中。
我们先将public修辞的属性和函数移到person中。并将Telephone类中的所有public方法变成委托函数,让其调用person类中的方法。
public class Person {
private String name;
private Telephone telephone = new Telephone();
private String telephoneNum;
private String areaCode;
public String getName() {
return name;
}
public Telephone getTelephone() {
return telephone;
}
public String getTeleNum() {
return telephone.getTelephoneNum();
}
public void setTelephoneNum(String telephoneNum) {
this.telephoneNum = telephoneNum;
}
public String getAreaCode() {
return areaCode;
}
public void setAreaCode(String areaCode) {
this.areaCode = areaCode;
}
public String getTelephoneNum() {
return telephoneNum;
}
}
public class Telephone {
private Person person = new Person();
public void setTelephoneNum(String telephoneNum) {
person.setTelephoneNum(telephoneNum);
}
public String getAreaCode() {
return person.getAreaCode();
}
public void setAreaCode(String areaCode) {
person.setAreaCode(areaCode);
}
public String getTelephoneNum() {
return person.getTelephoneNum();
}
}
到这里,编译测试一下,是否正常运行,结果是否正确,如果没有问题的话,我们再将Telephone类中的public方法改为private,切断外界与telephone的交流,改而将其所有引用通过Person类的相应方法来完成调用。
Hide Delegate(隐藏“委托关系”)
客户通过一个委托类来调用另一个对象,并调用后者的相应函数,这时,我们可以在这个委托类中建立客户所需的所有函数,然后隐藏委托关系。也就是对客户隐藏这层委托关系,而只让委托关系发生在委托类与被委托类之间。其实,这种重构手法可以说是对委托关系进行一次封装。
如果客户通过调用委托类,得到了被委托对象,然后调用后者的函数,这里,也就是说,客户知道了这层委托关系,如果后面,委托关系发生了变化,客户这边也需要进行相应的调整,而这显然是不合理的。我们应该通过在委托类与被委托类间进行一层封装,隔离变化,而让客户只需要调用相应的对外暴露的函数而不需要承担变化所带来的风险。使变化发生的风险是可控的。我们以人和部门的例子来说明一下怎么来使用Hide Deletage重构手法来隐藏委托关系。
public class Person {
private Department department;
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
public class Department {
private String manager;
public Department(String manager) {
this.manager = manager;
}
public String getManager() {
return manager;
}
}
如果客户需要知道某个人的经理叫什么名字,它需要这样做:
john.getDepartment().getManager()
而这样子的话,客户就知道了DepartMent类的实现原理了,于是客户知道Department中存储的是经理的信息。如果对客户隐藏Department可以减少客户与Department的耦合。为解决这个问题,我们在Person中建立一个简单的委托函数:
public String getManager() {
return department.getManager();
}
而让客户直接调用Person类中的getManager()函数,这样子很好的解决了客户与Department类耦合的问题,同时也隔离了变化,客户端不需要知道其内部是怎么实现了,客户端只需要调用其相应暴露的方法就可以了,至于变化,是委托与被委托之间来处理的,与客户无关。
Remove Middle Man(移除中间人)
某个类做了过多的简单委托动作,而这种动作已经带来了不好的影响,这时,我们可以让客户直接调用受托对象。这与Hide Deletage手法也是相反的,至于什么时候用何种方法,这里没有一个明确的答案,当你觉得在服务对象里多次重复写同样的方法给你造成麻烦时,可能这时,就需要使用Remove Middle Man重构手法来改变这一现状了。
具体做法如下:
- 在服务类中建立一个函数,用以获取受托对象
- 对于每个委托函数,在服务类中删除该函数,并让需要调用函数的客户转为直接调用受托对象。
在Hide Deletage重构手法中,我们隐藏了Department类,而在Person类中创建了相应的委托行为,用以暴露Department的方法。而随着需要的不断变化,如果Department类中有越来越多的方法需要对外暴露,而每暴露一个方法,都需要在Person类中创建该方法的委托,这时,就是需要使用Remove Middle Man了。也就是对Hide Deletage中的代码进行一次复原。
Introduce Foreign Method(引入外加函数)
你需要为提供服务的类增加一个函数,而你无法修改这个服务类,这时,你可以在客户类中建立一个函数,并以第一参数形式传递这个服务类对象。
这种情况主要说的是,当你需要调用某个服务类的某个函数来完成服务类提供的相应功能时,此时,服务类没有提供完成相应功能的这个函数,而本来通过服务类就可以完成相应功能的时候,我们需要通过在客户端中外加函数来替服务类来完成此功能,而日后,只要条件成熟了,你可以修改服务类的代码时,你就需要把这个外加函数添加到服务类中。
只要是通过外加函数实现的服务,其实都是临时的解决方法,只是权宜之计,而最终我们都是需要想办法将其本应该由服务类提供的函数添加回服务类本身。外加函数的具体做法分为:
- 在客户类中建立一个函数,用来提供你需要的功能。这个函数不应该直接调用客户类中的任何特性,如果需要,可以使用参数的形式传递进来。
- 以服务类实例作为该函数的第一个参数传入。
- 将该函数注释为:”外加函数 此函数应该在服务类中实现”
比如:我需要跨过一个收费周期。原本代码像这样:
Date newStart = new Date(previousEnd.getYear(),previousEnd.getMonth(),previousEnd.getDate() + 1);
我可以将赋值运算右侧提炼到一个独立的函数中,这个函数就称为一个外加函数,如果可以,应该将其添加到Date服务类中。
Date newStart = nextDay(previousEnd);
//此方法为外加函数,应该添加到Date类中。
private static Date nextDay(Date date) {
return new Date(previousEnd.getYear(),previousEnd.getMonth(),previousEnd.getDate() + 1);
}
Introduce Local Extension(引入本地扩展)
你需要为服务类提供一些额外函数,但你无法修改这个类。建立一个新类,使它包含这些额外函数,让这个扩展类成为源类的子类或者包装类。也就是相当于是将上面的外加函数添加到了一个新的类中,而这个类继承了服务类,也就变像的将函数添加到了服务类中。当然,如果可以修改源码,最好的办法还是在源服务类中进行添加相应函数。
如果只需要一两个函数扩展的话,那也大可不必新建一个类来做此操作。直接使用Introduce Foreign Method的方式来完成就可以了。而如果超过这个限度,外加函数就很难以控制它们了。所以,你需要使用一个单独的类将这些外加函数独立出来。还需要使用这个类要么继承服务类,要么对服务类进行包装。我们将这种情况统称为local extension(本地扩展)。
所谓本地扩展是一个独立的类,但也是被扩展类的子类:它提供源类的一切特性,同时额外添加新的特性。在任何地方你使用源类型,都可以使用本地扩展来取而代之。
本地扩展的具体做法为:
- 建立一个扩展类,将它作为原始类的一个子类或者包装类
- 在扩展类中加入转型构造函数 如果是子类化,转型构造函数应该调用适当的父类的构造函数。如果是包装,转型构造函数应该接收被包装类对象,并将其以实例变量的形式保存起来。
- 在扩展类中增加新的特性。
- 在需要调用新特性的地方,将调用源对象改为调用扩展对象。
- 将针对源服务类增加的所有外加函数都搬移到扩展类中。
6.13重新组织数据
Self Encapsulate Field(自封装字段)
你直接访问一个字段,但你发现与字段的耦合关系并得越来越难以维护,当需要对字段进行修改时,所有直接对片段的修改点都需要被重新修改。而且无法对字段的修改进行控制,也就是字段的值是不可控的,这也容易导致相应的风险。解决方法就是对这个字段进行private封装,并添加相应的访问函数。
这种方式我想就不必浪费口舌了,我相信所有使用过java的人,都会明白这个道理。
Replace Data Value with Object(用对象来替换数据值)
你有一个数据项,需要与其他数据和行为一起使用才有意义。比如,定单和客户、人和手机号码等等,在最初的时候,我们可能新建了一个定单类,而把客户作用定单的一个数据项,而随着业务的扩展,我们需要为客户添加相应的信息,此时,如果还是在定单类里进行扩展,就会导致职责不清、高耦合等问题;以或者我们创建了一个person类,并将电话号码当作person类的一个数据项,来存储电话号码,但是后来,对电话号码进行了细分,需要格式化、抽取区号等等的操作。这时我们就需要将客户或者电话号码从相应的寄生类中抽取出来,单独的自成一类来进行扩展,解除强耦合的关系。
接下来,我们以定单和客户的关系来说明一下用对象替换数据值的方法。我们以定单和用户的例子来进行说明。
public class Order {
private String customer;
public String getCustomer() {
return customer;
}
public void setCustomer(String customer) {
this.customer = customer;
}
}
上面有一个定单类,类里面使用字段来记录客户信息。并提供了获取客户和设置客户信息的相应函数。我们现在需要将记录客户信息的customer字段抽取出来单独创建一个类来进行客户信息的记录操作。
首先我们创建一个Customer类,然后将Order类中的字段移到customer类中,并在构造函数中接收此字段的信息,然后提供相应的访问函数。
public class Customer {
private String name;
Customer(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
我们创建了一个name的字段,这里的字段名不需要跟order的一样,只需要都是String类型即可。创建完后,我们需要将order类中和customer字段相应的都改为调用Customer新类。这里我们首先将字段的类型修改为新类的类型,然后修改相应的取值/设值函数。
public class Order {
private Customer customer;
public Order(String customer1) {
customer = new Customer(customer1);
}
public String getCustomer() {
return customer.getName();
}
public void setCustomer(String customer1) {
customer = new Customer(customer1);
}
}
这里需要对setCustomer()函数进行说明一下,因为之前我们的customer是一个String的值对象。所以这里我们有你有我 替换时,也需要使用值对象,而值对象的特点就是不可被修改。所以这里我们每次设值都会创建一个新的对象,因为不能对原来的对象进行修改,如果修改就变成了引用对象了,而引用对象并不符合原来的定义。当然这里也可以修改为引用对象,但这并不不是本重构方法所要说的,下面会有关于值对象到引用对象的重构手法。
这里我们还需要使用rename method来对相应函数进行修改,让其更能符合修改后意思表达。比如这里的getCustomer()修改为
public String getCustomerName() {
return customer.getName();
}
因为这里获取的就是客户名称的函数。同样的相应的参数名也做一下修改。
public Order(String customerName) {
customer = new Customer(customerName);
}
public void setCustomer(String customerName) {
customer = new Customer(customerName);
}
OK,此项重构到此以完成。
Change Value to Reference(将值对象修改为引用对象)
你从一个类衍生出许多彼此相等的实例,而你希望将它们替换为同一个对象。这时,你可以将这个值对象变成引用对象。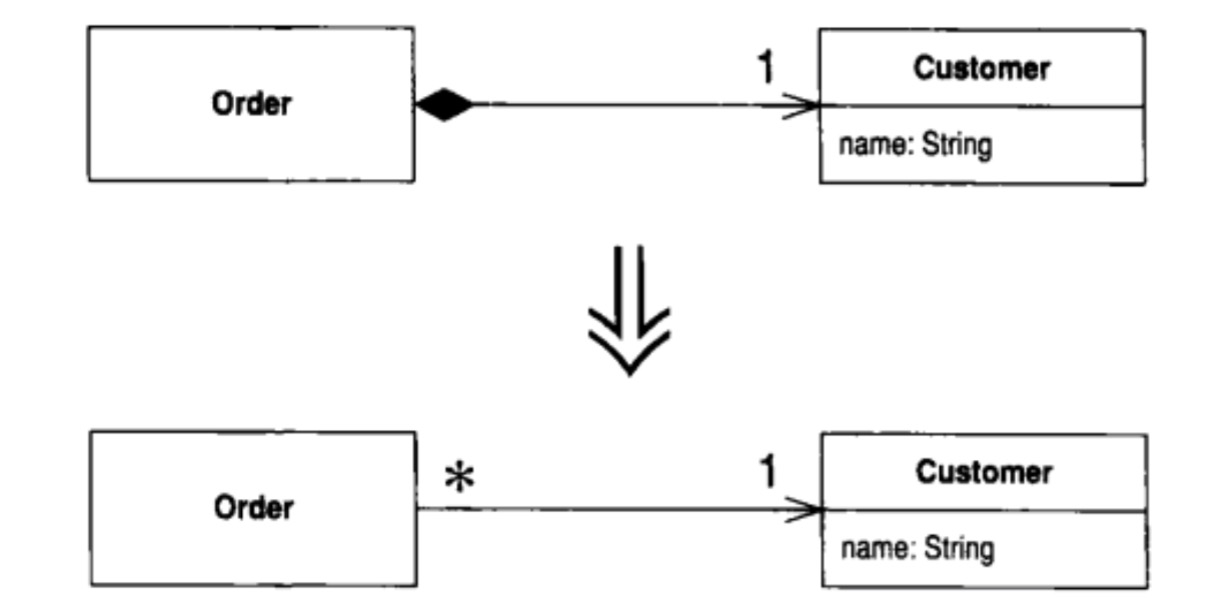 从图上可以看出,我们通过值对象转换成引用对象,将定单与客户的关系从一对一,变成了一对多,这也更符合现实的情况。
从图上可以看出,我们通过值对象转换成引用对象,将定单与客户的关系从一对一,变成了一对多,这也更符合现实的情况。
要在引用对象和值对象之间做出选择有时并不容易,有时候,你会使用一个简单值对象(一般指的就是基本数据类型的对象)来保存某些简单的数据,而后,需求的增加,你可能会希望给这个对象加入一些可修改的数据,并确保对任何一个对象的修改都能影响到所有使用此对象的地方。这时候你需要将值对象修改为引用对象。
我们在replace data value with object重构留下的代码开始,对其进行继续重构,让其满足对现实事物的描述。先来看看Customer类:
public class Customer {
private String name;
public Customer(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
下面是Order类:
public class Order {
private Customer customer;
public Order(String customerName) {
customer = new Customer(customerName);
}
public String getCustomer() {
return customer.getName();
}
public void setCustomer(String customerName) {
customer = new Customer(customerName);
}
}
在Order类中的setCustomer(String customerName)函数中我们使用创建对象的方式来模拟值对象,以致于每一个定单对应一个新的用户,而现实生活是多个不同定单可能对应的都是同一个用户,所以我们要使用change value to reference的方式来进行重构。
首先我们使用replace constructor with factory method来进行对象的创建
public static Customer create(String name) {
return new Customer(name);
}
private Customer(String name) {
this.name = name;
}
然后改变Order对象对customer对象的创建方式:
public Order(String custosmerName) {
customer = Customer.create(custosmerName);
}
接下来,为了避免重复创建对象,满足同一个customer对象,只应该存在一个对前提下,我们将所有存在的customer对象预先创建好,并存储到了一个静态的集合中,每当order类调用customer的静态工厂函数创建对象时,我们就从此集合中取出相应的对象进行返回。
private static Map<String, Customer> mCustomerInstance = new HashMap<>();
{
new Customer("zhangshan").store();
new Customer("lisi").store();
new Customer("wangwu").store();
}
private void store() {
mCustomerInstance.put(name, this);
}
这里我们使用静态代码块初始化存在的Customer对象后,将其通过store()函数将其存入到HashMap集合中进行存储。
现在,我们需要修改工厂函数:
public static Customer create(String name) {
return mCustomerInstance.get(name);
}
这样就保证了同一对象不会被多次创建。也使得订单和客户变成了多对一的关系。符合现实生活。
Change Reference to Value(将引用对象改为值对象)
你有一个引用对象,很小且不可变,而且不易管理,这时,你需要将此引用对象改为值对象。
这个重构方式刚好和change value to reference相反,这里要说明一下的是,每个重构手法都是根据相应的场景而进行使用的,而没有一定要使用什么重构手法去硬套。也就是没有哪种手法比其它手法更好,有的只是相应的重构手法对应特定的代码场景。
如果引用对象开始变得难以使用,也许就应该将它改为值对象。值对象有一个特点,就是它们应是不可改变的,也就是,在任何时候,通过同一对象的同一个查询函数返回的值都应该是相等的。如果你遇到了引用对象做着值对象的操作时,就需要将此引用对象变成值对象。
Replace Array with Object(使用对象来替换数组)
你有一个数组,数组里的每个元素都各自代表不同的东西。此时,可以使用对象来替换数组,将数组里的每个元素在对象里通过字段来进行表示。 这里说的就是数组里的每个元素转换成对象里的相应字段,然后提供设值/取值函数的过程。
这里说的就是数组里的每个元素转换成对象里的相应字段,然后提供设值/取值函数的过程。
Duplicate Observed Data(复制“被监视数据”)
你有一些领域数据置身于GUI控件中,而领域函数需要访问这些函数。这里主要说的是界面和业务逻辑,领域数据就是通过界面所获得的数据,也就是用户输入的数据,而领域函数就是处理业务逻辑的函数。通过Observable模式,用以同步界面和业务逻辑中的重复数据。 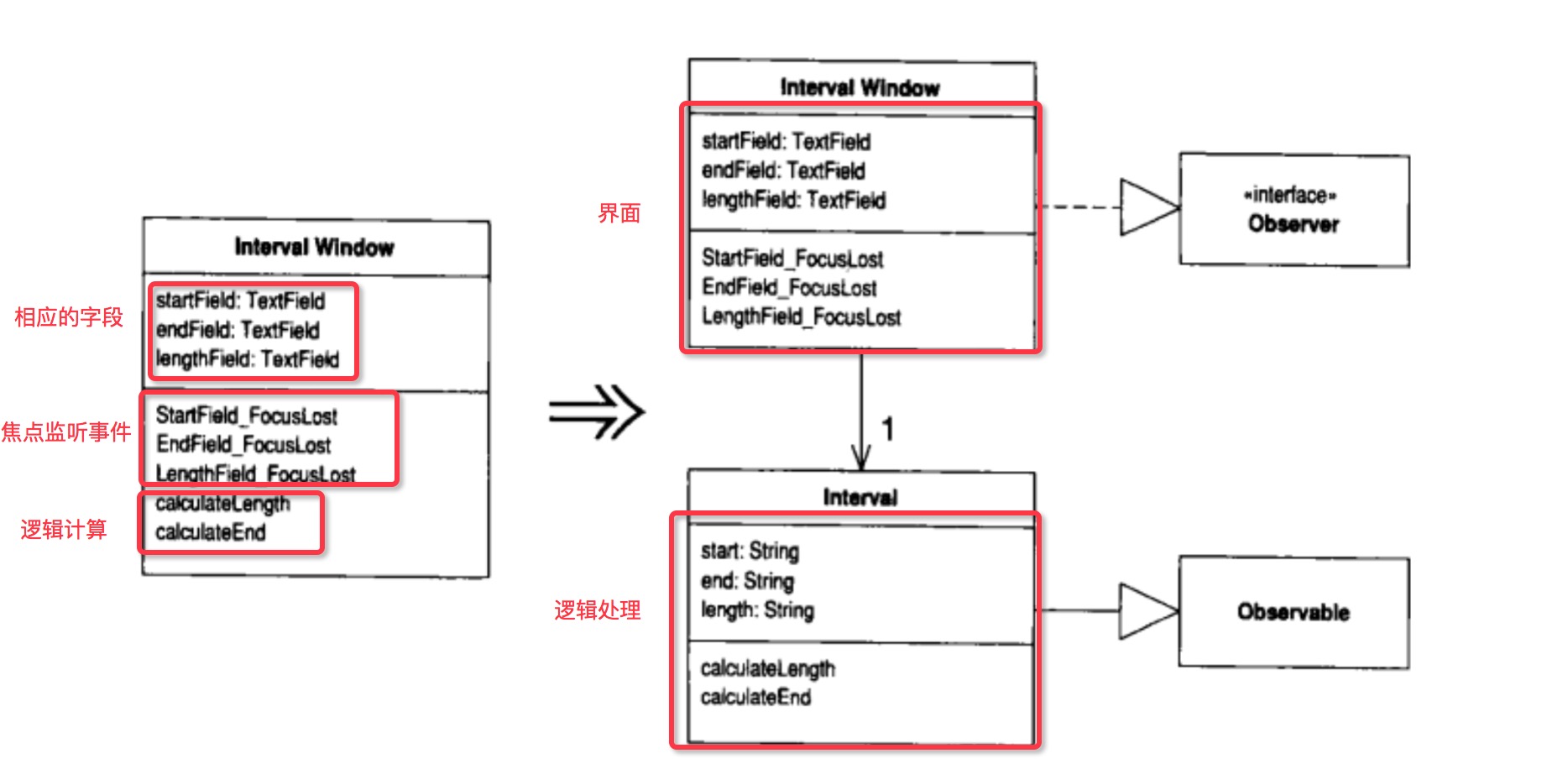 从图上可以看出,主要做的工作就是对界面和业务逻辑解耦,通过
从图上可以看出,主要做的工作就是对界面和业务逻辑解耦,通过Observable设计模式来进行数据的同步更新。
Change Unidirectional Association to Bidirectional(将单向关联改为双向关联)
两个类都需要使用对方的某些特性,但其间只有一条单向连接。此时,添加一个反向指针,并使修改函数能够同时更新两条连接。这里的反向指针指的就是被引用类指向引用类的那条引用对象。而修改函数指的是对类中指针(也就是引用对象)进行修改的函数,如在order类中的指针是customer对象,然后通过setCustomer()函数来对Customer进行修改,这里的setCustomer()函数就是修改函数。
做法:
- 在被引用类中增加一个字段,用以保存反向指针。
- 决定由哪个类——引用端还是被引用端来控制关联关系。
- 在被控制端建立一个辅助函数,让其可以访问对应的引用对象。
- 如果既有的修改函数在控制端,让它负责更新反向指针。
- 如果既有的修改函数在被控制端,就在控制端建立一个控制函数,并让既有的修改函数调用这个新建的控制函数。
我们还是以Order和Customer的例子来做说明:
在例子中,Order引用了Customer而没有反向引用。
public class Order {
private Customer customer;
而由于一个客户可以拥有多个订单,所以这里我们需要在Customer类中添加引用Order类的反向指针,而且还是不重复多个订单,所以这里我们将这个字段定义为一个Set类型的集合。
根据做法二所说的,我们接下来需要指定谁来做控制端。这里我们有一些原则。
- 如果两者都是引用对象,而其间的关联是一对多的关系,那么就由’拥有单一引用’的一方来承担
控制者角色。比如:一个客户可拥有多份订单,这就是一对多的关系,而Order类中的customer引用是一的一方,也就是order类中拥有customer这个单一引用,所以关系由Order来控制。- 如果某个对象是组成另一个对象的部件,也就是另一个对象是依赖此对象来创建的,那么由后者来承担控制关系。
- 如果两都都是引用对象,而其间的关联是”多对多”的关系,那么由哪一方来控制关联关系,都无所谓。
本例中,Order类为控制对象,根据做法三,我们需要在Customer建立一个辅助函数,让其可以访问Customer类中的orders定单集合。Order的修改函数将使用这个辅助函数对指针两端对象进行同步控制。我们将这个辅助函数命名为friendOrders(),相应的代码如下:
public Set friendOrder() {
return mOrders;
}
现在,根据做法四:我要改变修改函数,也就是setCustomer(),令其更新反向指针。
public void setCustomer(Customer customerArgs) {
if (customer != null) {
customer.friendOrder().remove(this);
}
customer = customerArgs;
if (customer != null) {
customer.friendOrder().add(this);
}
}
这里的操作主要是先让对方删除你的指针,也就是我们这里的
customer.friendOrder().remove(this);
然后,再将你的指针指向一个新的对象
customer = customerArgs;
最后,让那个新的对象将把它的指针指向你。
customer.friendOrder().add(this);
如果你希望在Customer中也能修改连接,就让它调用控制方法。
public void addOrder(Order order) {
order.setCustomer(this);
}
如果一份定单也可以对应多个客户,也就是多对多的关系,那么重构后就是下面这样:
public void addCustomer(Customer addCustomer) {
addCustomer.friendOrder().add(this);
mCustomers.add(addCustomer);
}
public void removeCustomer(Customer customer1) {
customer1.friendOrder().remove(customer1);
mCustomers.remove(customer1);
}
public void addOrder(Order order) {
order.addCustomer(this);
}
public void removeOrder(Order order) {
order.removeCustomer(this);
}
Change Bidirectional Association to Unidirectional(将双向关联改为单向关联)
两个类之间有双向关联,但其中一个类如今不再需要另一个类的特性,这时,我们应该去除不必要的关联,将双向关联变为单向关联。
双向关联不仅增加了两个类的复杂度,而且导致两类间的高度耦合,除非有必要使用,不然,尽量使用单向关联。当我们使用了双向关联,只要有机会我会都应该将双向关联改为单向关联。去除关联关系最主要的就是去除相互类中依赖的指针,也就是对应的保存指针的字段。
我们还是以上例中的Order和Customer来说明此重构手法吧。
public void addCustomer(Customer addCustomer) {
addCustomer.friendOrder().add(this);
mCustomers.add(addCustomer);
}
public void removeCustomer(Customer customer1) {
customer1.friendOrder().remove(customer1);
mCustomers.remove(customer1);
}
public void addOrder(Order order) {
order.addCustomer(this);
}
public void removeOrder(Order order) {
order.removeCustomer(this);
}
这里order和customer是双向关联关系,而我们发现只有当Customer存在的时候,Order才会存在。也就是说,这里Customer和order只能是一对多的关系,其中Customer为一,order为多,也就是一个Customer对应多个Order。所以,我们需要将Order中的Customer指针移除。同时需要检查是否有依赖customer字段存在,(这里为了区分,将字段前加上“”).如果确实有,那么需要为此提供替代品。
我们需要研究所有读取这个字段的函数,以及所有使用这些函数的函数。同时需要使用另一种方式提供Customer对象,一般意味着我们需要将Customer对象作为参数传递到函数中。
public double getDiscountedPrice() {
return getPrice() * (1 - customer.getdiscount());
}
修改成通过参数传递的方式,而非使用指针对象:
public double getDiscountedPrice(Customer customer) {
return getPrice() * (1 - customer.getdiscount());
}
另一种做法就是修改其取值函数,使其在不使用_customer字段的前提下,提供一个Customer对象。我们将Order类中的取值函数替换成这样:
public Customer getCustomer() {
Iterator iterator = Customer.getInstance().entrySet().iterator();
while (iterator.hasNext()) {
Customer customer = (Customer) iterator.next();
if (customer.containCustomer(this)) {
return customer;
}
}
return null;
}
然后,我们在Order类所有引用到_customer字段的地方,使用getCustomer()函数进行替换。当我们移除_customer后,其实两个类的关系就变成单向关系了。但是即使我们移除了_customer字段,两个类间的相互依赖关系依然存在。
Replace Magic Number with Symbolic Constant(使用常量替换魔法数)
你在代码中使用了数字,如果这个数字有特别的意思,这时,你应该根据数字所代表的意思创建一个常量,然后使用这个常量去替换这个数字。 正如图上所展示的,就是将数字替换成静态常量,没有其它的。
正如图上所展示的,就是将数字替换成静态常量,没有其它的。
Encapsulate Field(封装字段)
你的类中有一个public字段,请将这个字段的权限设置为private,然后为此字段提供取值/设值函数。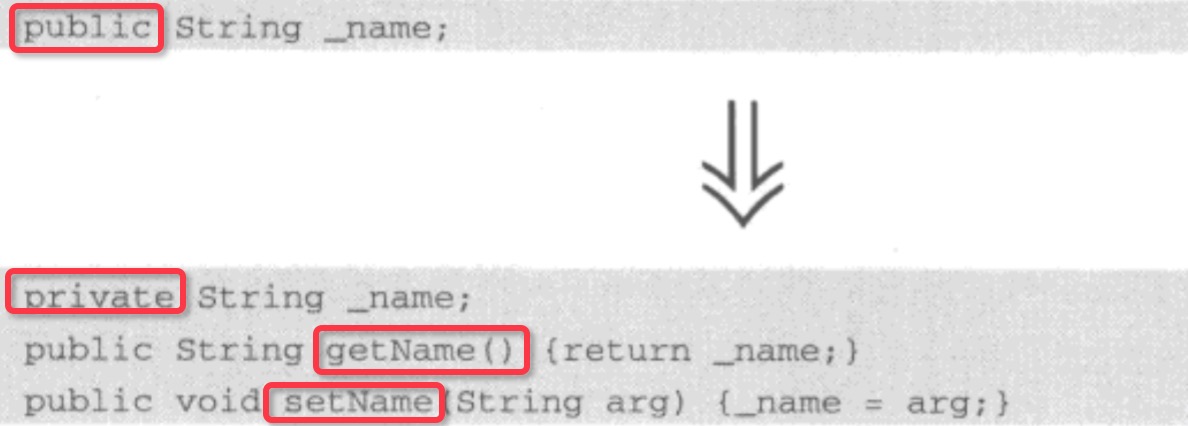 这个也没什么好说的,最简单的字段封装。
这个也没什么好说的,最简单的字段封装。
Encapsulate Collection(封装集合)
有个函数返回一个集合,让这个函数返回该集合的一个只读副本,并在这个类中提供添加/移除集合元素的函数。
这里主要说的就是当你返回这个集合时,这个集合使用集合工具中的封装集合的方法unmodifiableXXX(),XXX代表相应的集合类型,让其返回一个只读也就是不可修改的集合。
public Set getCollection() {
return Collections.unmodifiableSet(data);
}
然后在这个集合所属的类中添加添加/移除集合元素的方法。
Replace Type Code with Class(以类取代类型码)
类中使用了数值类型码,但它不影响类的行为。不影响类的行为可以理解为类中不会根据不同的类型码而执行不同的操作。这种情况下,可以使用一个类替换该数值类型码。这样做的好处有两点:1.可以对这个类进行类型检验,通过类来控制传值的范围,如果是直接通过数值传值的话,可能会传递非法的值。2.将与类型码有关的逻辑抽离到了一个单独的类中,解耦便于维护。 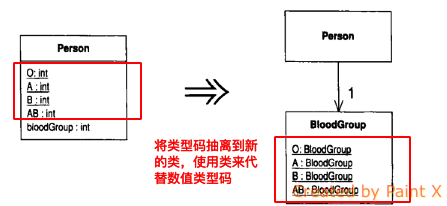
这里我们使用人和血型的例子来说明此重构手法的使用.首先来看一下Person类的代码:
public class Person {
public static final int O = 0;
public static final int A = 1;
public static final int B = 2;
public static final int AB = 3;
private int bloodGroup;
public Person(int bloodGroup) {
this.bloodGroup = bloodGroup;
}
public int getBloodGroup() {
return bloodGroup;
}
public void setBloodGroup(int bloodGroup) {
this.bloodGroup = bloodGroup;
}
}
我们将Person类中的类型码移到新创建的类BloodGroup中,然后使用BloodGroup类来代替类型码。
public class BloodGroup {
public static final BloodGroup O = new BloodGroup(0);
public static final BloodGroup A = new BloodGroup(1);
public static final BloodGroup B = new BloodGroup(2);
public static final BloodGroup AB = new BloodGroup(3);
public static BloodGroup[] bloodGroup = {O, A, B, AB};
private int mCode;
public BloodGroup(int code) {
this.mCode = code;
}
public int getCode() {
return mCode;
}
public static BloodGroup code(int code) {
return bloodGroup[code];
}
}
然后,我们将Person类中的类型码使用新建类BloodGroup进行替换。
public class Person {
public static final int O = new BloodGroup(0).getCode();
public static final int A = new BloodGroup(1).getCode();
public static final int B = new BloodGroup(2).getCode();
public static final int AB = new BloodGroup(3).getCode();
private BloodGroup bloodGroup;
public Person(int bloodGroup) {
this.bloodGroup = BloodGroup.code(bloodGroup);
}
public int getBloodGroup() {
return bloodGroup.getCode();
}
public void setBloodGroup(int bloodGroup) {
this.bloodGroup = BloodGroup.code(bloodGroup);
}
}
接下来我们需要修改Person类中的函数,让其使用BloodGroup来代替整数类型码。
public Person(BloodGroup bloodGroup) {
this.bloodGroup = bloodGroup;
}
public int getBloodGroupCode() {
return bloodGroup.getCode();
}
public BloodGroup getBloodGroup() {
return bloodGroup;
}
public void setBloodGroup(BloodGroup bloodGroup) {
this.bloodGroup = bloodGroup;
}
这里我们使用rename method的方法将原来的返回int类型的getBloodGroup()函数修改为getBloodGroupCode(),并添加了相应的取值/设值函数及对构造方法进行了修改。
修改完成后,我们需要修改调用Person类的地方,让其使用新的类型来进行调用。比如,构造函数的调用,原来是这样的:
Person person1 = new Person(Person.A);
现在变成了:
Person person = new Person(BloodGroup.A);
从传递数值类型码变成了传递对象,避免了不合法数值,变得更安全了。
然后,相就的取值函数也发生了变化,原来是这样的:
person.getBloodGroupCode();
现在变成了:
person1.getBloodGroup().getCode();
设值函数原来是这样的:
person.setBloodGroup(Person.A);
现在同样也变成了:
person.setBloodGroup(BloodGroup.A);
替换完毕后,我们需要把相应的与数值类型码整数相关的函数和字段删除。下面都是需要删除的代码:
public static final int O = new BloodGroup(0).getCode();
public static final int A = new BloodGroup(1).getCode();
public static final int B = new BloodGroup(2).getCode();
public static final int AB = new BloodGroup(3).getCode();
private BloodGroup bloodGroup;
public Person(BloodGroup bloodGroup) {
this.bloodGroup = bloodGroup;
}
public Person(int bloodGroup) {
this.bloodGroup = BloodGroup.code(bloodGroup);
}
好了,到这里,我们就把使用数值类型码的地方全部替换为对象了,此次重构也就完成了。
Replace Type Code with Subclasses(以子类取代类型码)
你有一个不可变的类型码,这个类型码会影响类的行为。此时,可以使用子类取代这种类型码,也就是将每个类型码变为由相应的子类去实现。
什么情况下使用这种重构手法呢?
一般是在像类中有switch或者if-else之类的条件表达式,根据不同的类型码状态去执行相应的动作,这种情况下可以使用子类来取代类型码,把宿主类当作基类,每个类型码作为一个子类去实现相应的特性,然后,将基类中的相应函数使用push down method的方式,移到相应的子类中。
什么情况不适合使用此重构手法呢?
- 如果有类型码在对象创建完成后发生了改变。
- 类型码宿主类已经有了相应的子类,而java中只支持单继承,这种情况我们需要使用
Replace Type Code with State/Strategy来使用多态去之实现。
Replace Type Code with Subslasses的好处在于:它把需要对“不同行为的了解”从类的用户转移到类自身。如果需要增加一个新的变化,只需要添加一个子类就行了。如果没有多态机制,这里我们需要对每次行为的增加,去修改每一处对类型码的判断。因此,如果以后需要增加新的行为,这项重构是非常有价值的。
这里我们使用雇员和薪资的例子来说明一下此重构手法。首先我们先来看看雇员类的代码:
public class Employee {
public static final int SALESMAN = 0;
public static final int ENGINEER = 1;
public static final int MANAGER = 2;
private int type;
Employee(int type) {
this.type = type;
}
public int getType() {
return type;
}
}
我们需要将类型码替换成宿主类的子类,这里我们以Engieer为例:
首先将宿主类中的获取Type的函数抽象出来:然后创建Engieer继承宿主类,实现getType()方法。
public class Engieer extends Employee {
Engieer(int type) {
super(type);
}
@Override
protected int getType() {
return Employee.ENGINEER;
}
}
同时,我们需要修改Employee的构造函数为工厂函数,让其根据相应type创建相应的类型码对象。
protected Employee(int type) {
this.type = type;
}
public static Employee getInstance(int type) {
switch (type) {
case SALESMAN:
return new Salesman(type);
case ENGINEER:
return new Engieer(type);
case MANAGER:
return new Manager(type);
default:
throw new RuntimeException("类型码输入错误,不存在此类型码");
}
}
这里我们不可避免的使用了switch语句,这里使用是可以接受的,因为这只是在创建相应对象时根据类型码进行了判断。这里的例子是很简单的,我们在使用此重构手法过程中,可能还会需要使用push down method等重构手法将相应基类的函数移到对应的子类中。
Replace Type Code with State/Strategy(使用状态/策略模式替换类型码)
你有一个类型码,它会影响类的行为,而你无法通过Replace Type code with subclasses来消除它。这时,你可以使用状态或者策略模式去取代类型码。这里主要说的是,你需要单独创建一个状态/策略基类,而不是使用宿主类来作为基类,然后通过类型码宿主类来对状态基类的引用,来根据不同的状态去执行相应的动作。
这里我们在前面6.8 将状态码转换为状态模式已经作为详细的说明。
Replace Subclass with Field(以字段取代子类)
你的各个子类之间唯一的差别就是返回常量数据的函数身上,也就是说唯一的差别只是返回常量数据的函数不同。此时,你可以修改这些函数,使它们返回超类中的某个新增字段,然后将子类销毁。
我们以男人和女人的例子来说明一下此重构手法。首先来看一下男人和女人类的超类Person类的情况。
public abstract class Person {
abstract boolean isMale();
abstract String getCode();
}
及其子类男人和女人的实现:
//男人
public class Male extends Person {
@Override
boolean isMale() {
return true;
}
@Override
String getCode() {
return "M";
}
}
//女人
public class Female extends Person {
@Override
boolean isMale() {
return false;
}
@Override
String getCode() {
return "F";
}
}
从上面的代码可以看出,男人和女人子类的getCode()方法返回了一个硬编码的值,这样子的情况就需要我们使用Replace Subclass with Field来将不必要的子类去除,减少由于子类继承的复杂度。
首先我们将两个抽象方法转换成字段的形式在父类中保存其状态。
首先我们在父类中分别声明两个工厂函数,让其调用Person的构造函数,用来创建男人对象和女人对象。
private boolean isMale;
private String code;
然后将上面两个字段作为构造函数的两个参数,让创建Person类时,传递相应的参数:
public Person(boolean isMale, String code) {
this.code = code;
this.isMale = isMale;
}
再在Person类中创建两个工厂函数,分别为创建男人和女人对象:
public static Person createMale(boolean isMale, String code) {
return new Person(isMale, code);
}
public static Person createFemale(boolean isMale, String code) {
return new Person(isMale, code);
}
最后,提供相应的取值函数。
public boolean isMale() {
return isMale;
}
public String getCode() {
return code;
}
到此之后,子类的功能就被搬移到了父类中,此时,我们就可以移除子类,而在其所有引用处,将其实现改为由父类来代替。